Kubernetes Scheduler Cache System
This is part of a series of blog posts exploring the Kubernetes kube-scheduler from the perspective of someone who has dug deep into the codebase.
Introduction
Today, we are going to deep-dive into the kube-scheduler cache component, which maintains its view of the cluster state. This component is the state machine that tracks pods through their lifecycle, manages node information, and provides snapshots for scheduling decisions. Understanding how this works is crucial for anyone who wants to understand scheduler behavior or troubleshoot scheduling issues.
Why the Cache Exists
There is a reason why the scheduler cannot trust the network.
When the scheduler decides that `pod X` fits on `node Y`, it sends a bind request to the API server, which then transmits it over the network and returns a confirmation. In a busy cluster, that round-trip might take hundreds of milliseconds.
So what does the scheduler do while waiting? The answer is documented in the code:

The scheduler receives pod and node events over the network via Kubernetes informers, which introduces several challenges:
The scheduler might not immediately be aware of changes.
The scheduler might miss intermediate state changes while retrieving updated lists.
The scheduler learns about the bind confirmation too late.
So, rather than waiting for API server confirmation, the scheduler assumes its decision will succeed and accounts for the resources. If this assumption is wrong, the cache has mechanisms to recover.
This is called optimistic scheduling, which the scheduler uses via the assumed-pod mechanism.
The Cache Architecture State Machine
The kube-scheduler cache is the scheduler’s reliable, up-to-date view of the cluster state, maintaining detailed information about nodes and pods to enable informed scheduling decisions without constantly querying the API server.
The cache stores the following key types of information:
NodeInfo: Detailed information about each node, including resources, labels, taints, and running pods.
PodInfo: Information about pods, including their resource requirements and constraints, now supports pod-level resource specifications (beta v1.34).
Assumed Pods: Pods that the scheduler optimistically believes will be bound to nodes.
Snapshot: A consistent view of the cluster state used for each scheduling attempt, ensuring all plugins see the same cluster state.
Dynamic Resource Allocation: Integration with DRA prioritized lists (beta v1.34).
The cache implements a state machine for pods, managing transitions from Initial → Assumed → Added → Deleted states, which is crucial for handling the asynchronous nature of pod binding.
Cache Management of Pod and Node Lifecycle
The scheduler’s operational flow, the cache manages lifecycles for both pods and nodes:
Pod Lifecycle in Cache
Initially, the pod is added to the Cache as an "Assumed Pod" when a scheduling decision is made.
Once the API Server confirms that a pod is bound to a node, the pod is updated in the cache from assumed to actual.
When the pod is deleted, it’s removed from cache entirely.
Node Lifecycle in Cache
Each node Added/Updated/Deleted event directly affects the NodeInfo within the cache.
NodeInfo maintains detailed information about each node’s resources, labels, taints, and running pods.
Snapshot Generation
To ensure all scheduler components operate on a consistent cluster view, the cache generates Snapshots, which are consistent views of the cluster state. These snapshots ensure that all plugins see the same cluster state during a scheduling cycle, maintaining consistency and preventing race conditions.
Overview of Scheduler Cache Architecture
Before going into the scheduler cache’s architecture, let’s walk through a detailed architecture diagram:
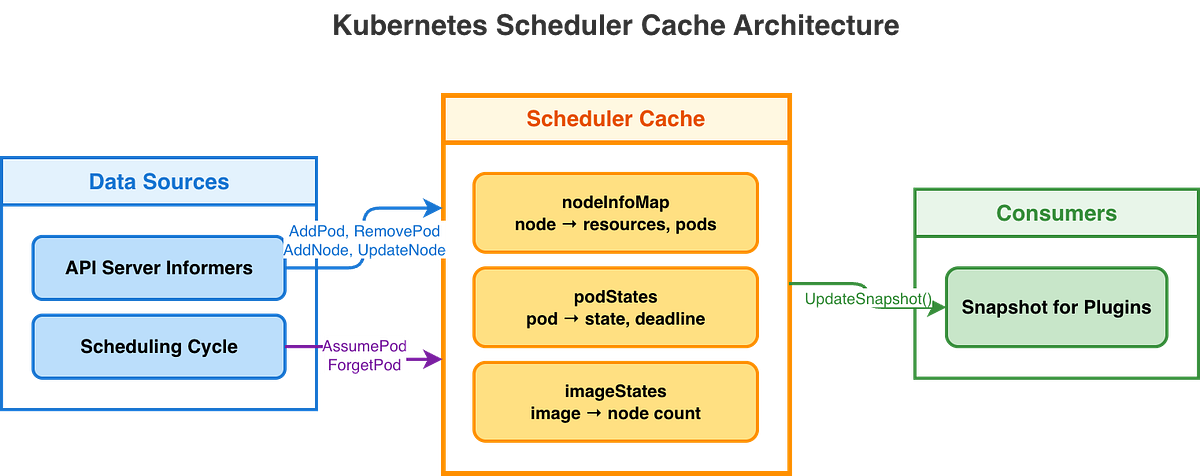
The diagram shows the scheduler cache architecture and how it manages pod states, including assumed pods with TTL, node information, image presence tracking, and consistent snapshots.
The Cache Implementation Structure
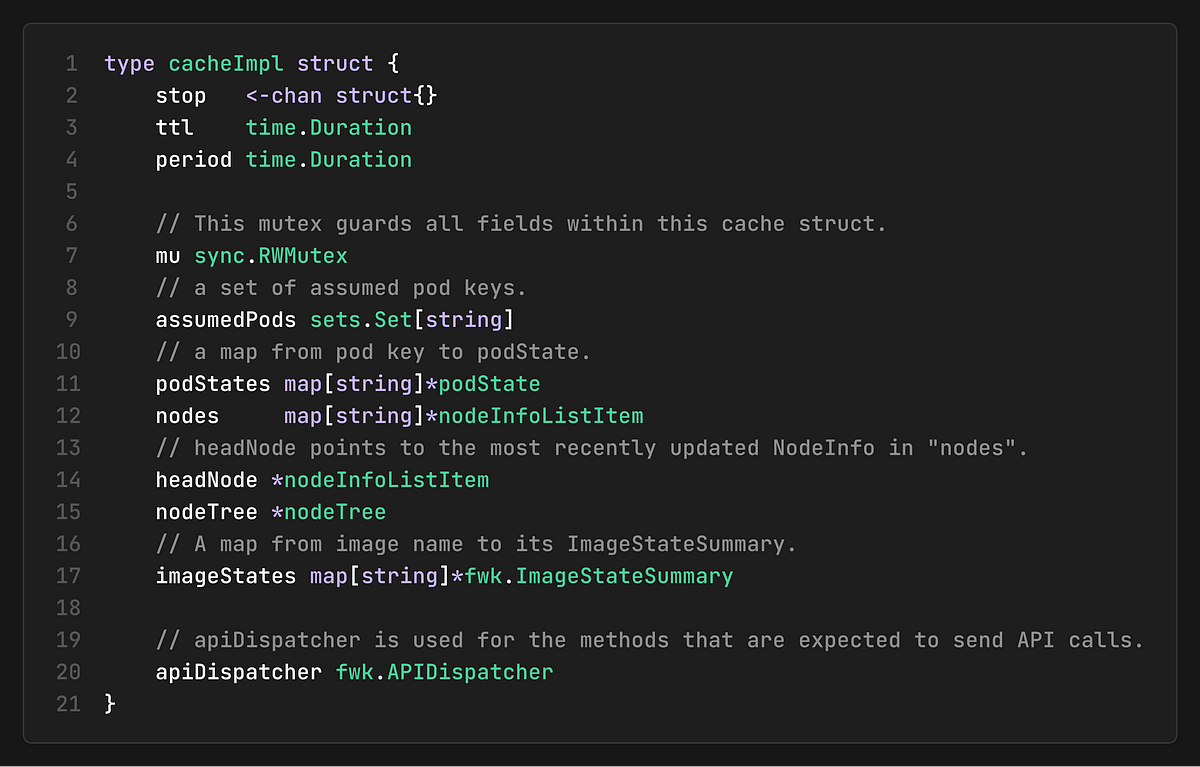
The cache maintains the following data structures:
assumedPods: A set of pod keys that are in the “assumed” state
podStates: A map from pod keys to their current state
nodes: A map from node names to node information items
nodeTree: A tree structure for efficient node lookups
imageStates: A map of image information for each node
Pod State Machine
The cache implements a state machine for pods, managing transitions from Initial → Assumed → Added → Deleted states.
Here is a detailed state machine diagram for the pod lifecycle within the cache:
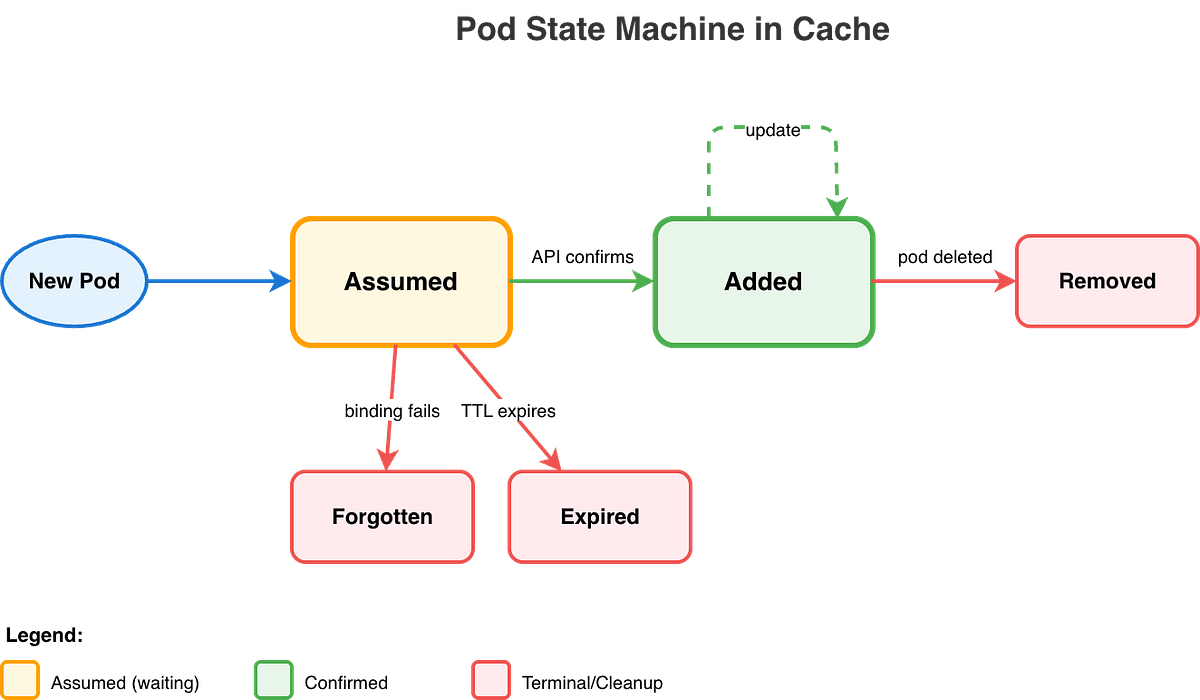
It shows how the scheduler handles optimistic assumptions, API confirmations, and cleanup operations.
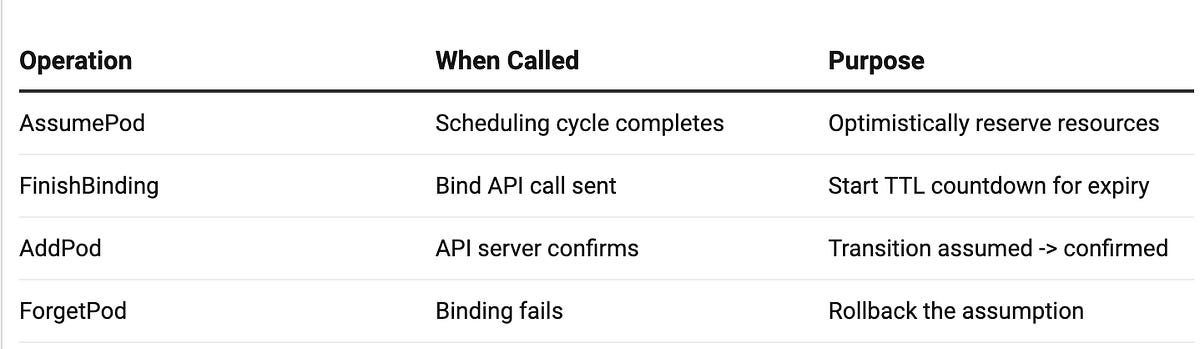
Cache Operations
The following flowchart illustrates how cache operations are handled, how different operations acquire appropriate locks, perform state checks, and manage pod lifecycle transitions with proper cleanup mechanisms:
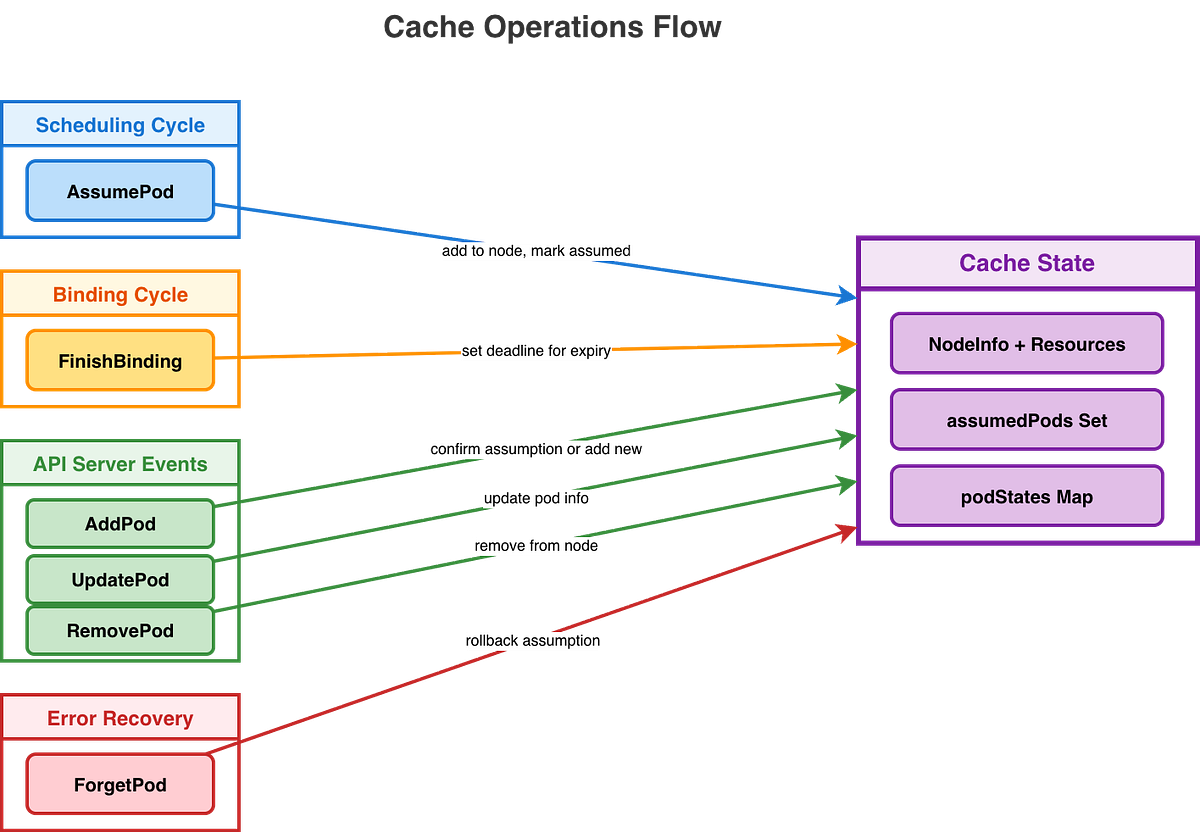
All cache operations are protected by a single `sync.RWMutex` for thread safety. The key insight is how these operations map to the pod lifecycle:
Background Cleanup
The following flowchart illustrates the background cleanup process, showing how the cache periodically removes expired assumed pods to maintain consistency and prevent stale state accumulation:
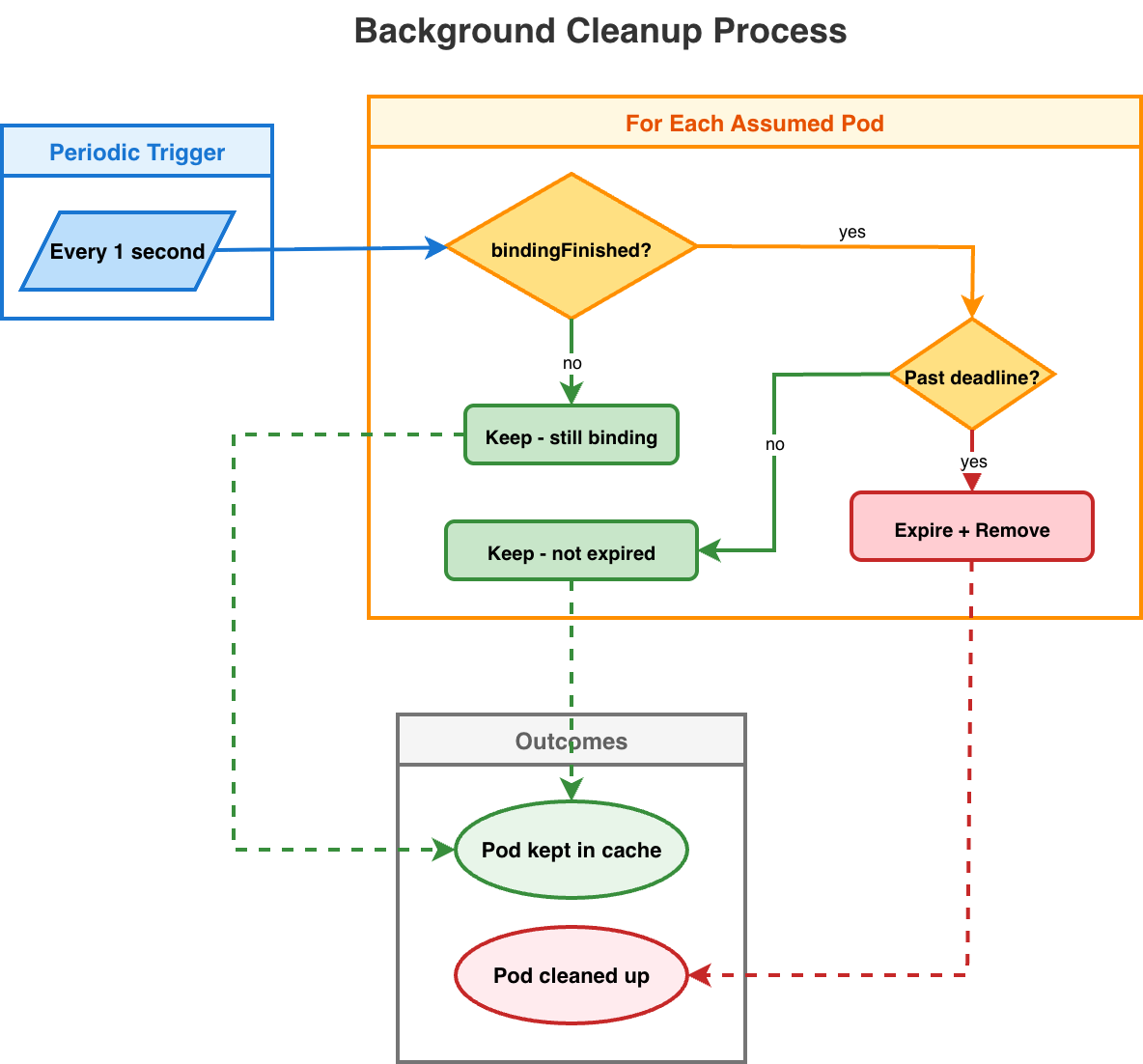
This background goroutine prevents memory leaks from pods that were assumed but never confirmed by the API server (i.e., due to network issues, crashes, etc.). A pod is only expired if:
bindingFinished = true: The bind API call was sent
Past deadline: Current time > deadline, which is set by `FinishBinding`
The cache implements a state machine for pods, as documented in the code comments:
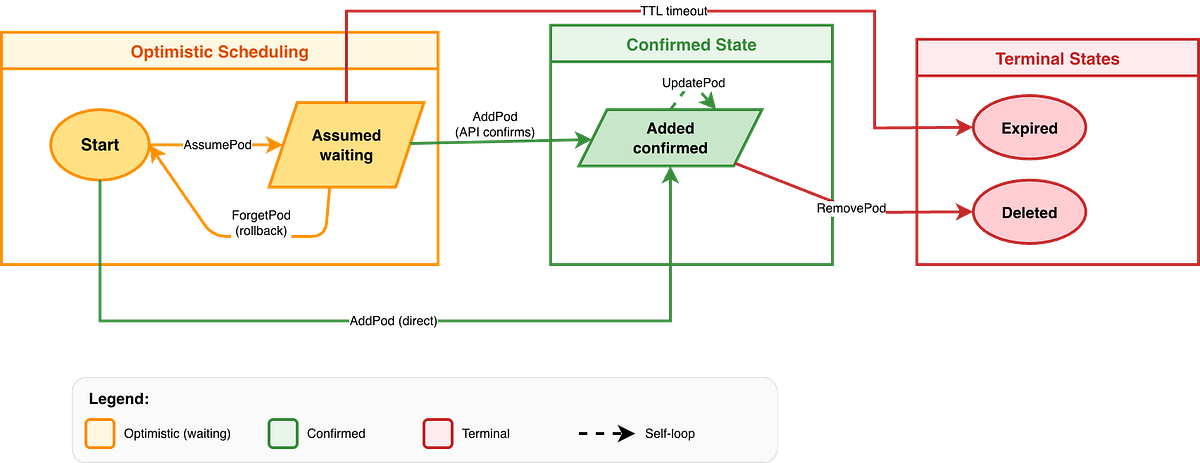
This state machine is crucial for understanding how the scheduler handles the gap between making a scheduling decision and that decision being confirmed by the API server. The “assumed” state allows the scheduler to optimistically update its view of cluster resources while waiting for confirmation.

Pod State Structure
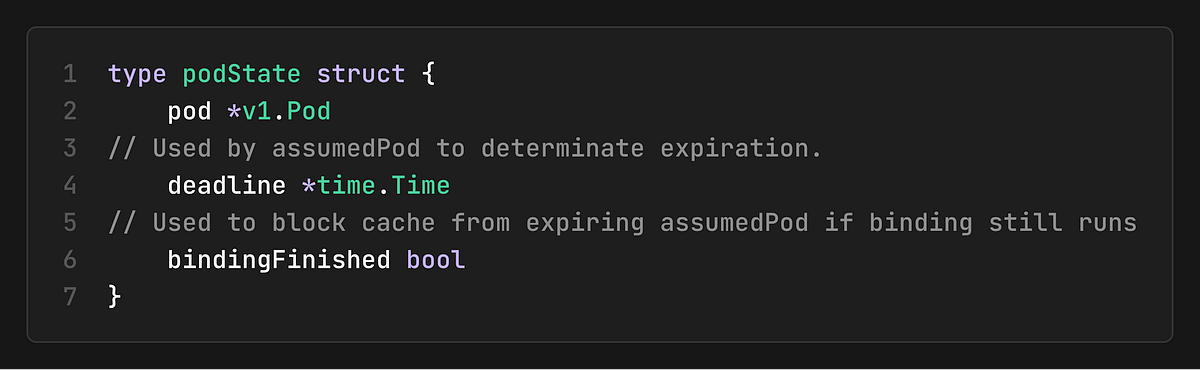
The `podState` structure tracks three pieces of information to enable the cache to handle the lifecycle of pods as they move through the scheduling process:
pod: The actual pod object
deadline: When an assumed pod should expire
bindingFinished: Whether the binding process has completed
Node Information Management
The cache maintains detailed information about each node in the cluster, organized in a doubly-linked list for efficient access.
Node Information List Structure
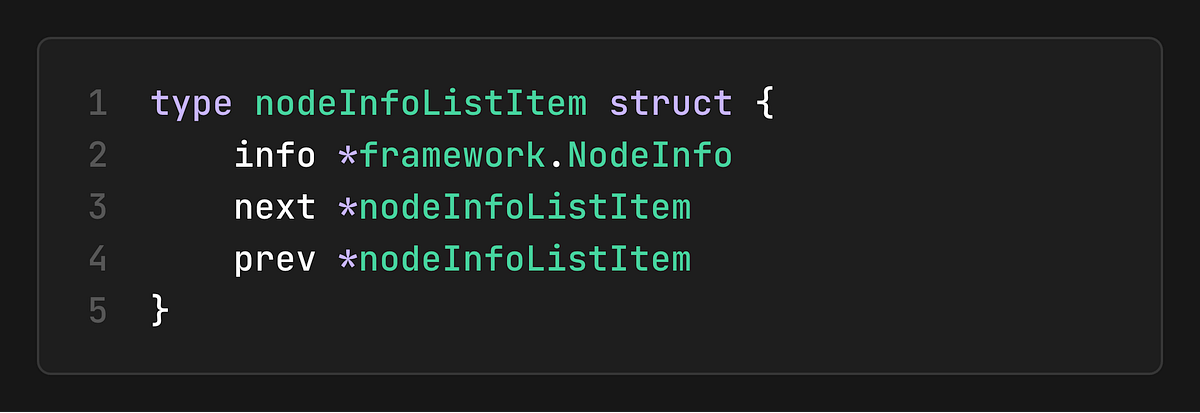
This design is particularly clever because:
LRU Access Pattern: The most recently accessed nodes are at the head
Efficient Updates: Moving a node to the head is O(1)
Snapshot Generation: The list order provides a natural ordering for snapshots
What’s Inside NodeInfo
Each `NodeInfo` contains all information that the plugin may need to make scheduling decisions:
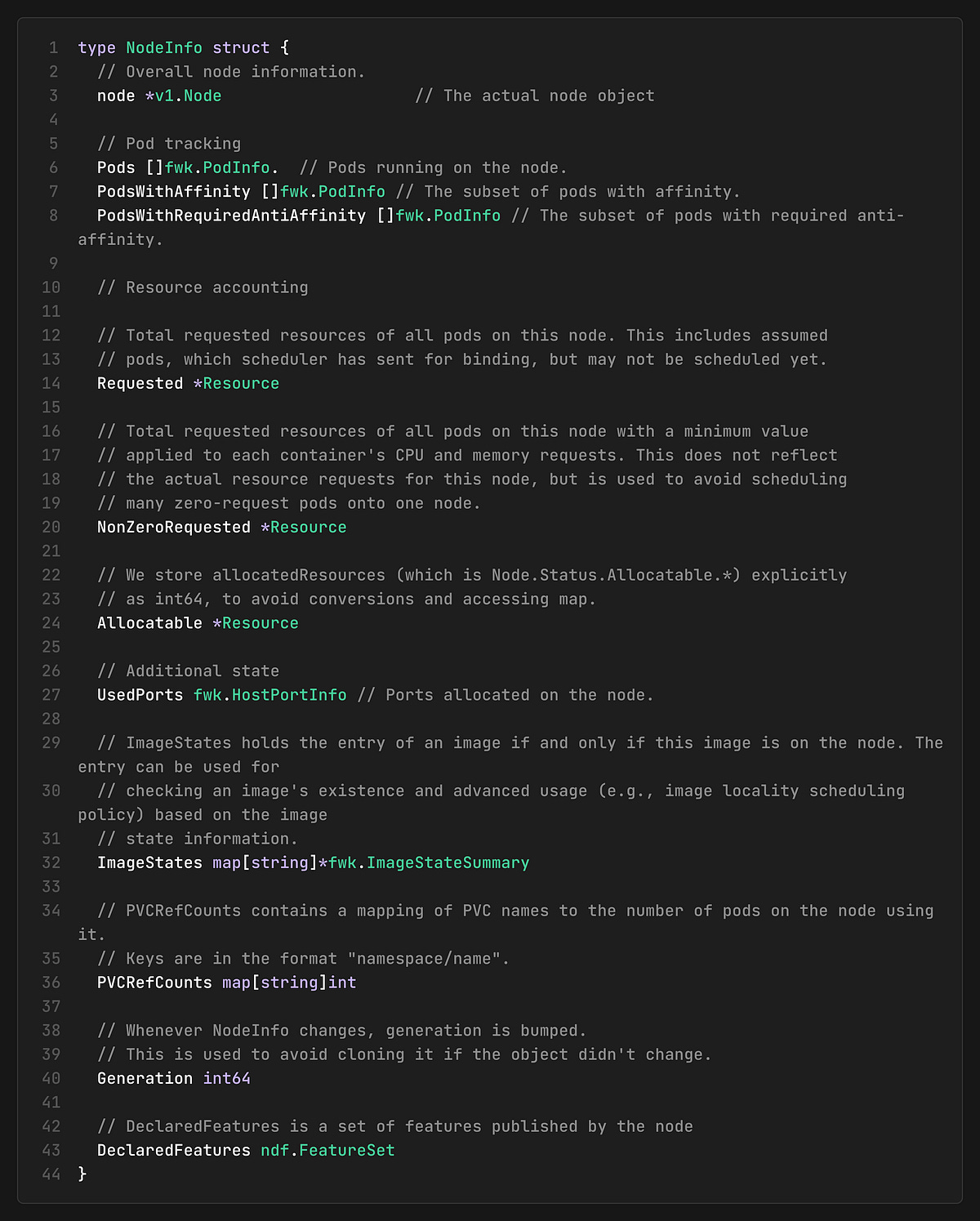
``Requested` includes assumed pods, so when the scheduler assumes a pod on a node, the resource accounting reflects it immediately. This is how the cache enables optimistic scheduling: subsequent scheduling cycles treat the resources as “used” even before the API server confirms the binding.
Node Tree and Efficient Queries
The cache maintains a `nodeTree` structure that enables efficient queries and node selection:
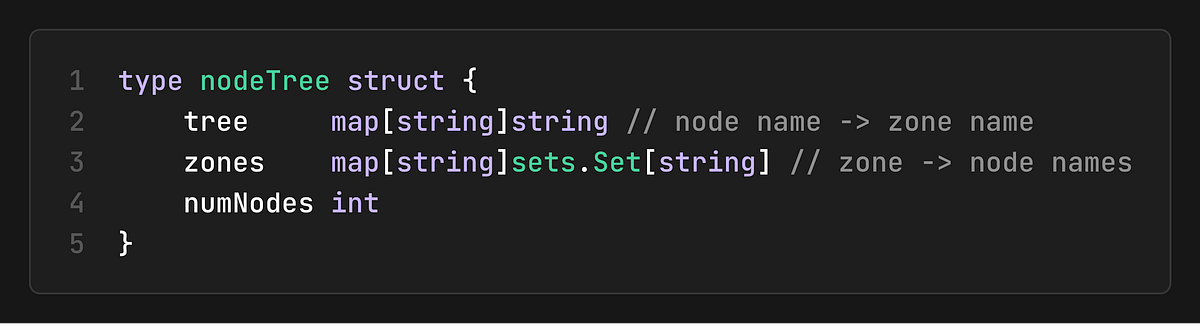
This tree structure allows the scheduler to:
Find nodes in specific zones
Balance workloads across zones
Implement zone-aware scheduling policies
Assumed Pods (Optimistic Scheduling)
The key aspect of the cache is how it handles assumed pods, allowing the scheduler to update its view (snapshots) while waiting for binding confirmation from the API server.
The AssumePod Process
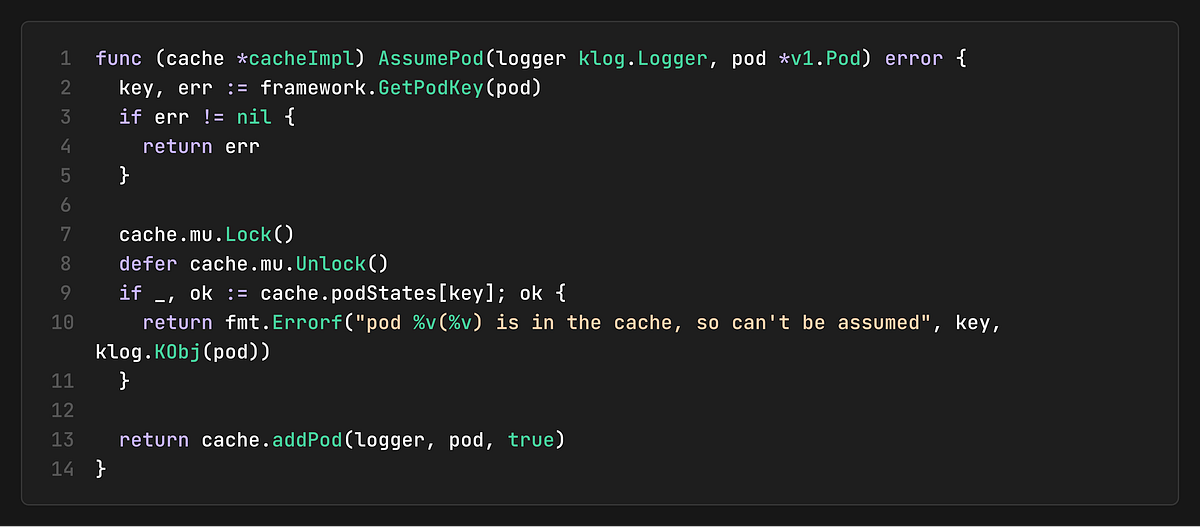
When a pod is assumed:
The cache adds the pod to its state
The pod is marked as “assumed” in the `assumedPods` set
The node’s resource usage is updated optimistically
The pod gets a deadline for expiration
Binding Completion and Confirmation
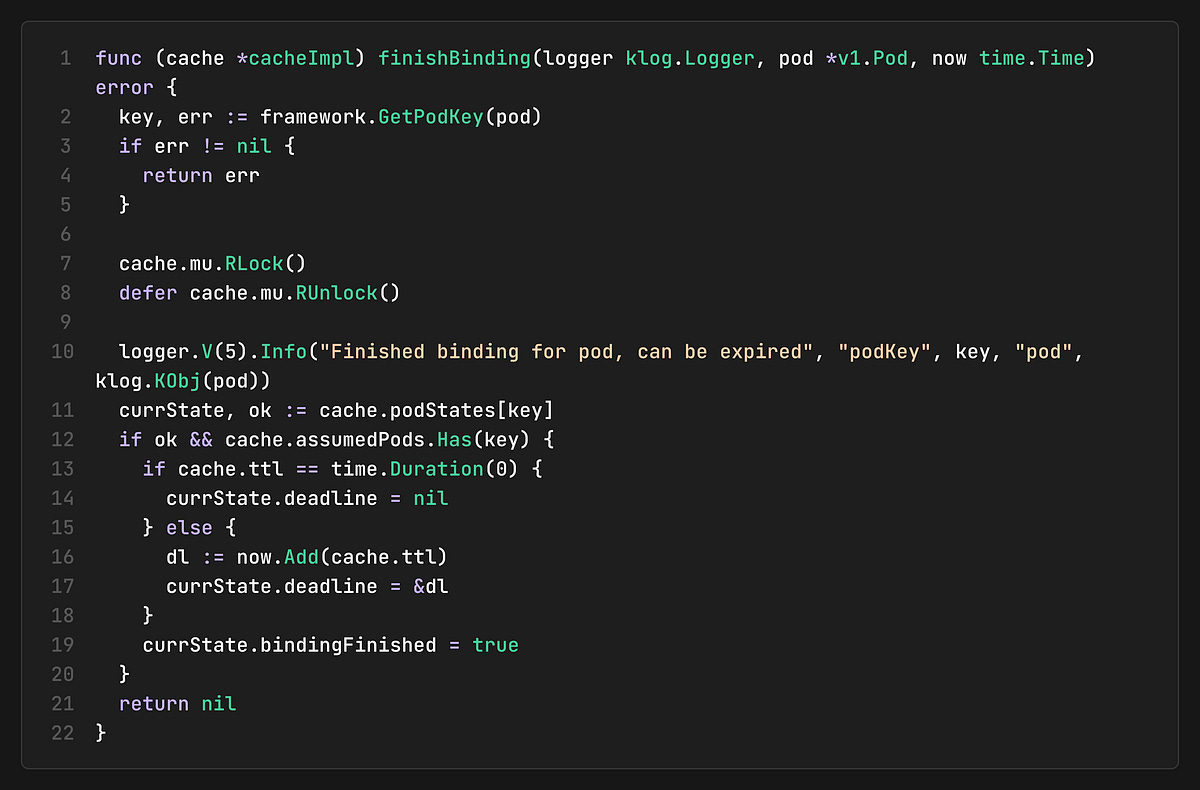
When the binding phase completes, the cache sets a deadline for the assumed pod. If the API server doesn’t confirm the pod within this deadline, it will expire and be removed from the cache. Code can be found here.
Pod Confirmation (From Assumed to Added)
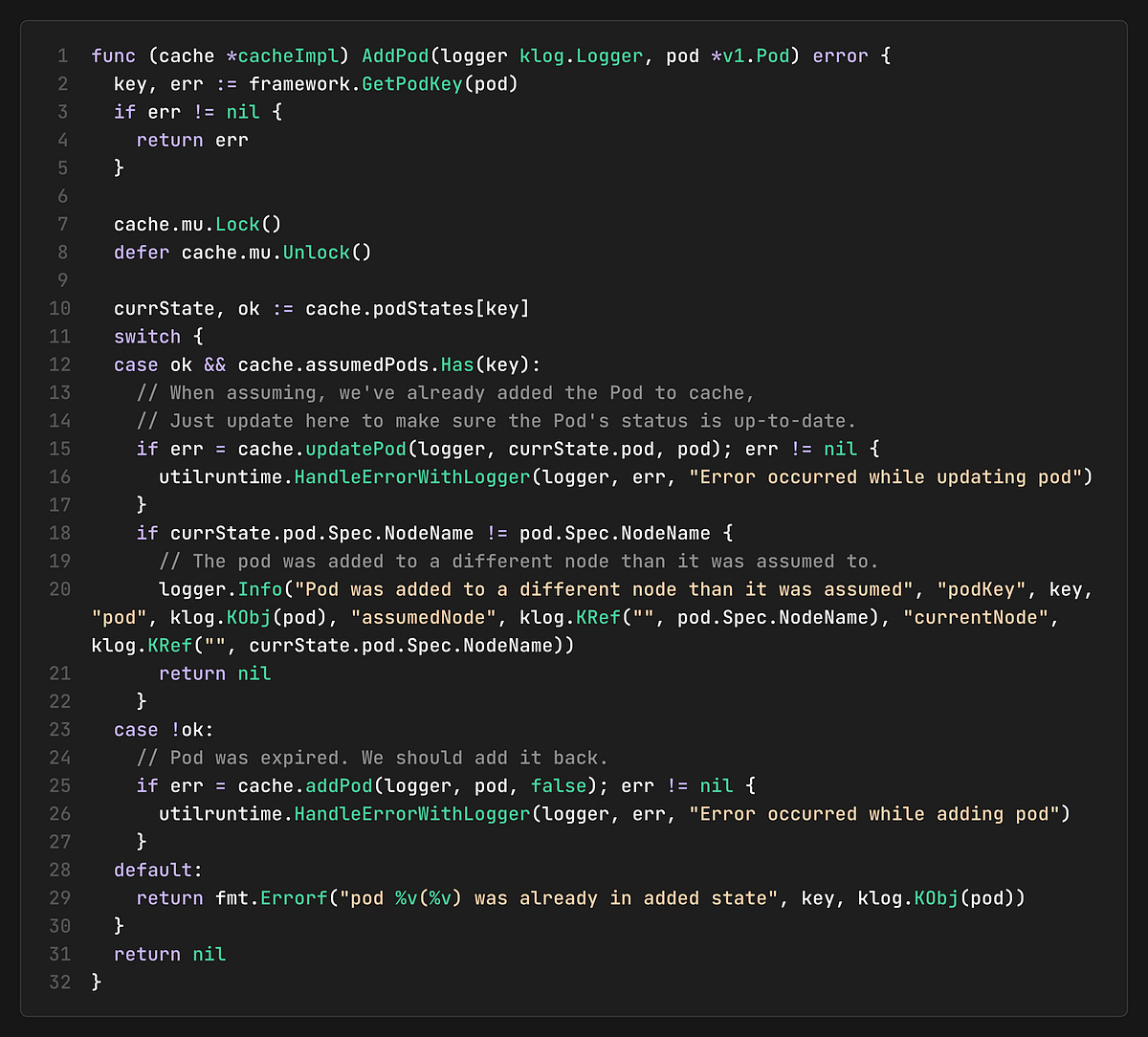
When the API server confirms a pod (via Add event), the cache transitions it from “assumed” to “added” state. This transition ensures consistency between the scheduler’s view and the actual cluster state. Code can be found here.
Snapshot Generation
The snapshot system ensures that all plugins in a scheduling cycle see a consistent view of the cluster state.
Snapshot Structure
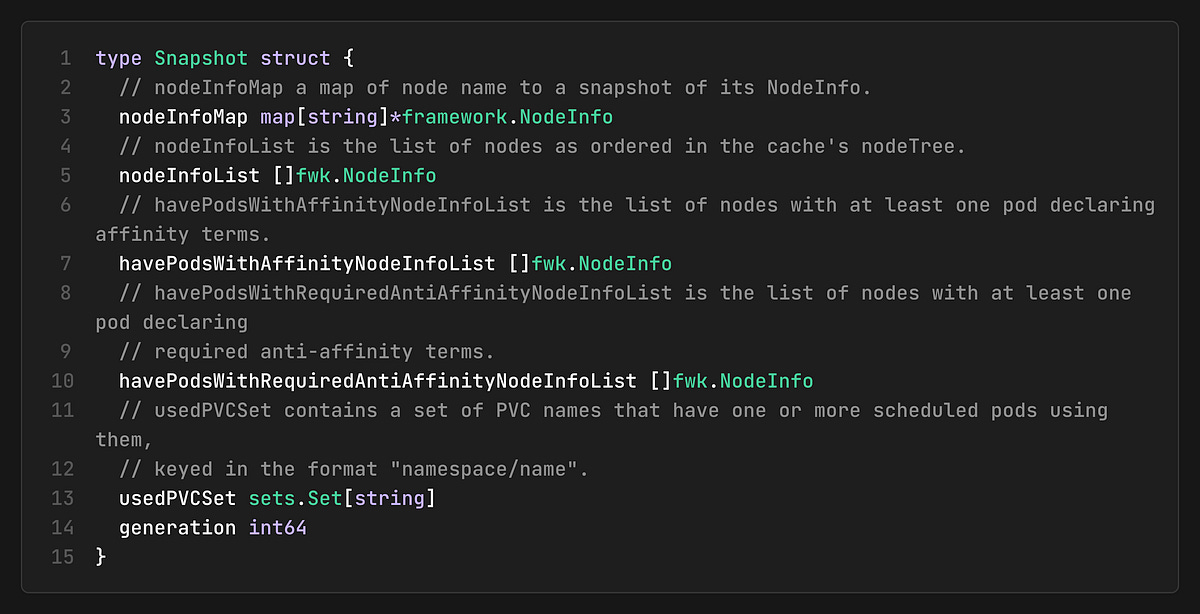
The snapshot includes several optimized data structures:
nodeInfoMap: Direct access to node information
nodeInfoList: Ordered list of nodes for iteration
havePodsWithAffinityNodeInfoList: Pre-filtered list for affinity plugins
havePodsWithRequiredAntiAffinityNodeInfoList: Pre-filtered list for anti-affinity plugins
usedPVCSet: Set of used PVCs for volume plugins
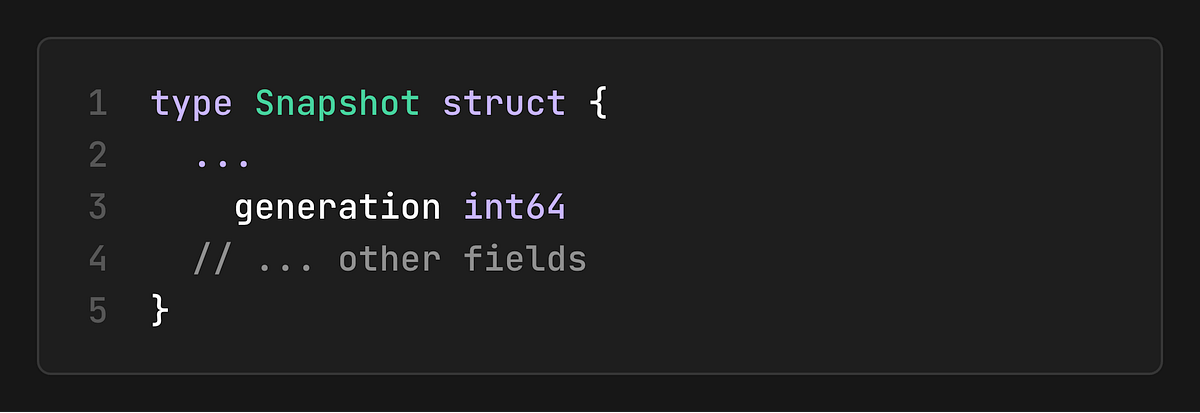
generation: Version number for incremental updates
Incremental Snapshot Updates
The cache implements incremental snapshot updates to avoid unnecessary work:
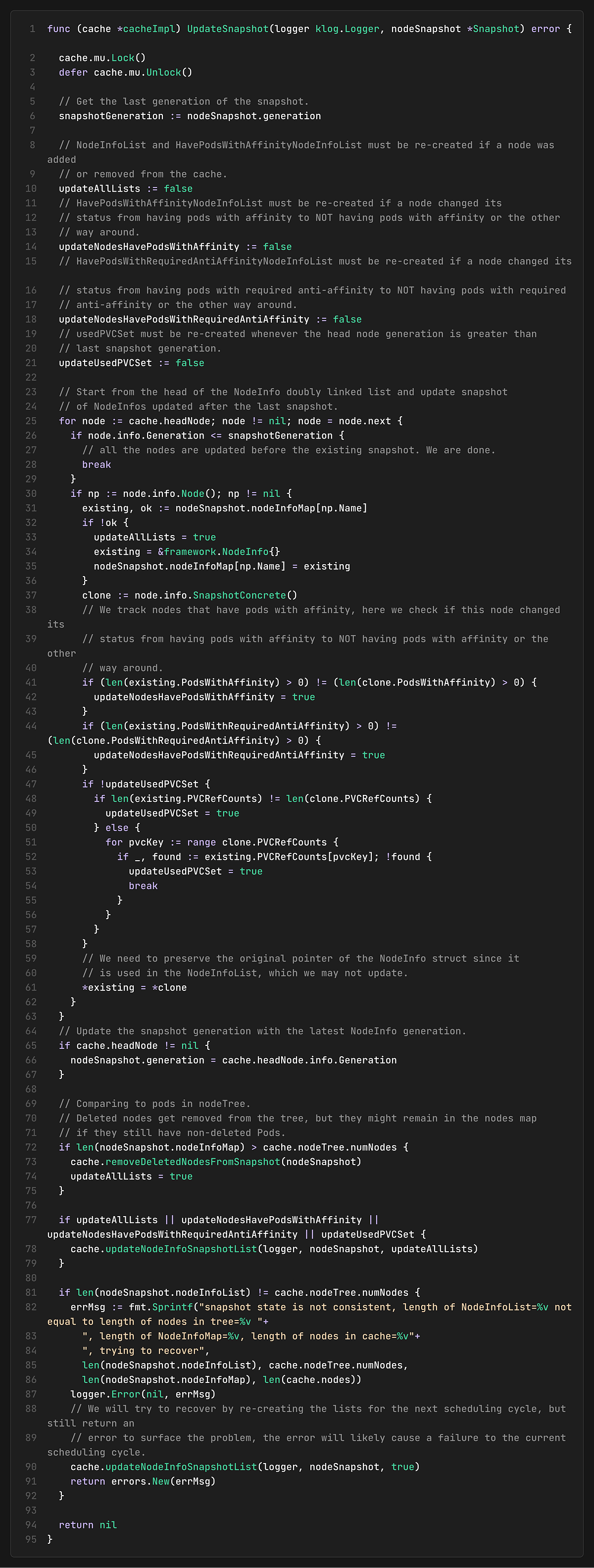
The cache tracks which parts of the snapshot need updating based on changes since the last snapshot. This incremental approach significantly improves performance by avoiding unnecessary work.
How Snapshots Are Used
The snapshot is taken once per scheduling cycle, then all plugins read from it:

This design ensures:
All plugins see the same cluster state during a scheduling cycle
No repeated cache access or lock contention during plugin execution
Changes to the cache during scheduling don’t affect in-flight decisions
Image State Management
The cache maintains image state information to enable efficient image-based scheduling decisions:
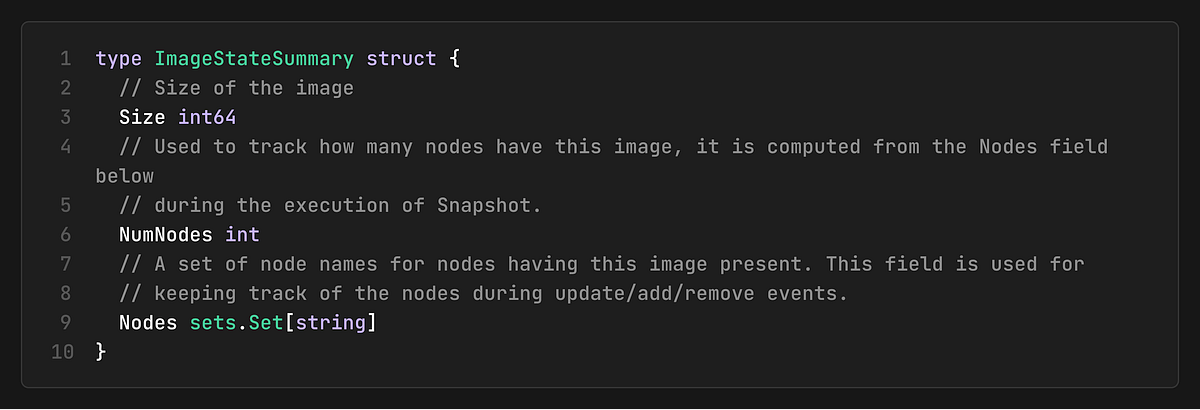
The cache tracks:
Size: The size of each image
NumNodes: How many nodes does this image have
This information is used by plugins (i.e., ImageLocality) to prefer nodes that already have required images.
Performance Optimizations
The cache implementation includes several performance optimizations:
Doubly-Linked List for LRU Access
The cache uses a doubly-linked list to maintain node information in LRU order, ensuring that frequently accessed nodes are at the head of the list and improving cache locality and snapshot generation performance:
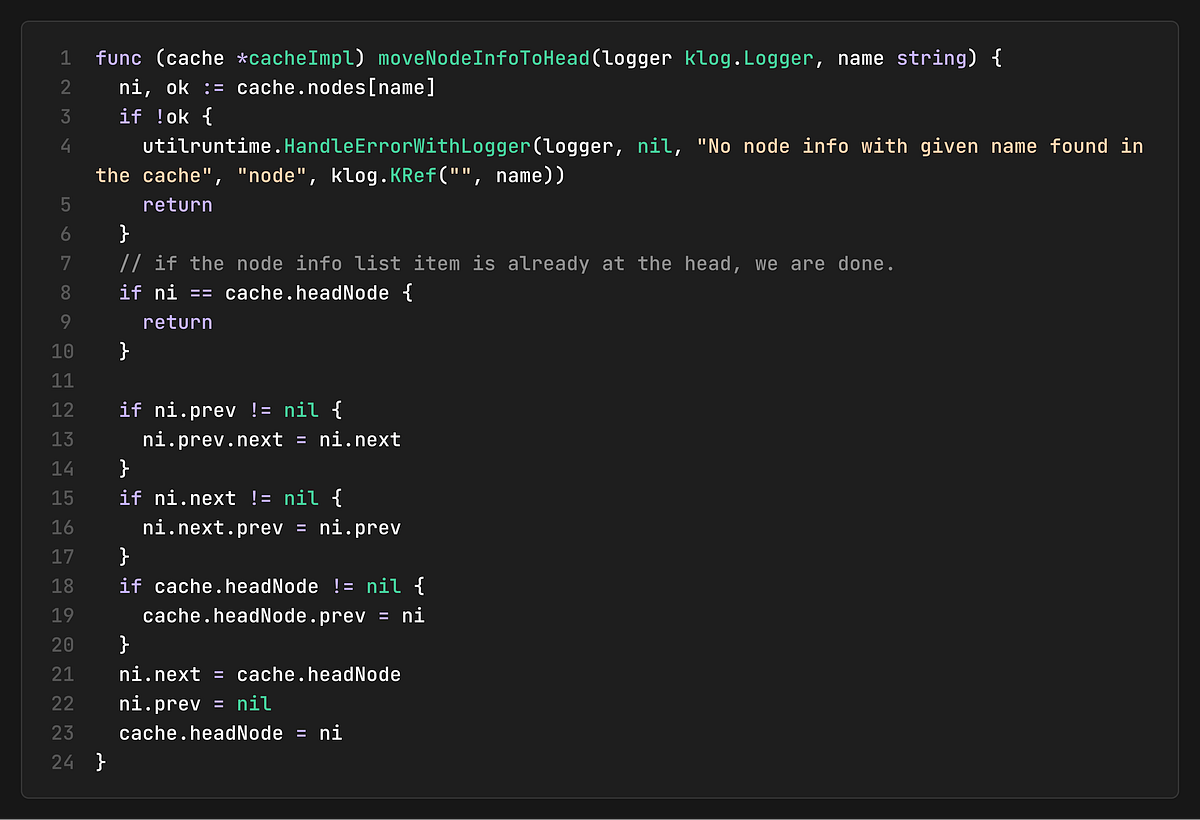
Pre-filtered Lists for Common Queries
The snapshot includes pre-filtered lists for common plugin queries:
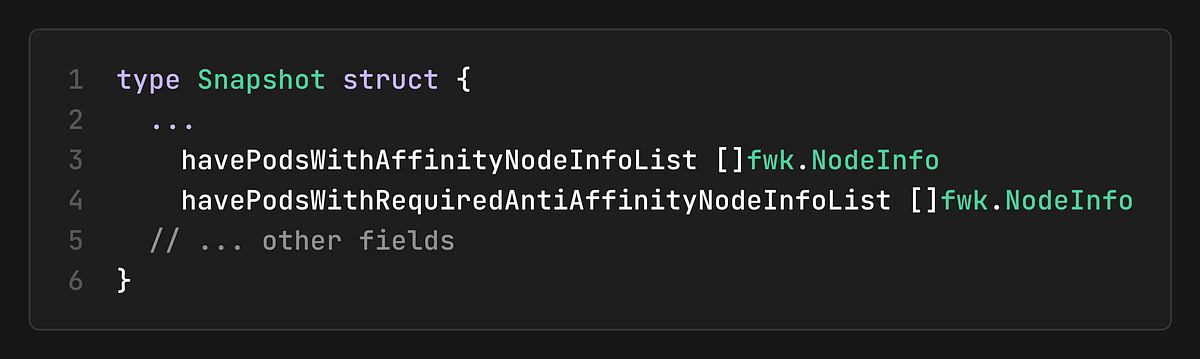
This optimization allows plugins to avoid iterating through all nodes when they only care about nodes with specific characteristics.
Generation-Based Incremental Updates
The cache uses generation numbers to enable incremental snapshot updates. This allows the cache to track changes since the last snapshot and update only the necessary parts:
Error Handling and Recovery
The cache implements error handling and recovery mechanisms:
Pod State Validation
The cache validates pod states during transitions:
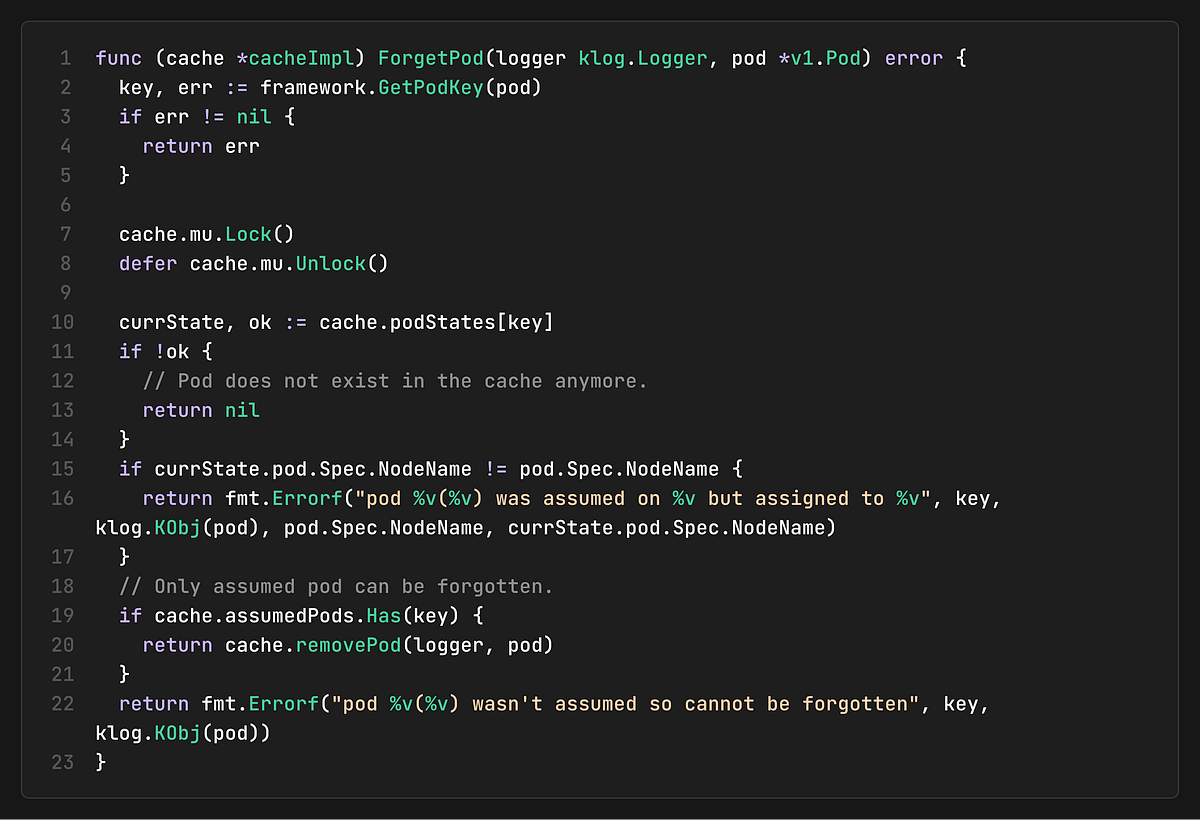
It ensures that pods can only be forgotten if they were previously assumed, maintaining cache consistency.
Node Cleanup
The cache automatically cleans up nodes when they have no pods to prevent accumulating stale node information:
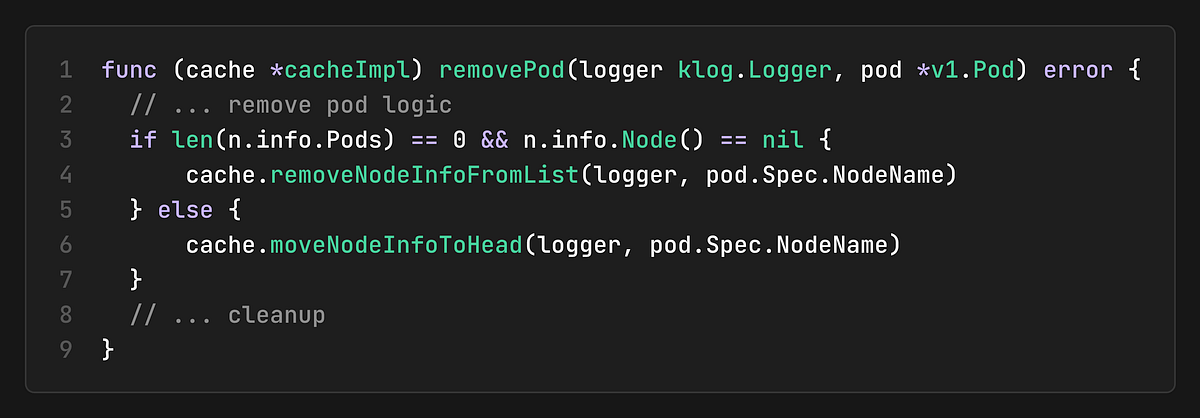
Cache Metrics
The cache exposes metrics for monitoring its state, which are updated during the background cleanup cycle:


These metrics are essential because they are capable of:
Detecting binding bottlenecks, since growing `assumed_pods` count points that bindings aren’t completing
Validating cache consistency by comparing pod/node counts with the actual cluster state
Capacity planning by understanding scheduler memory usage
In the next post, we’ll dive into the Scheduling Cycles and API Integration, exploring the synchronous and asynchronous scheduling phases, the API Dispatcher that handles binding operations, and how the assumed pod mechanism bridges the cache with the binding process.
This analysis is based on Kubernetes v1.35.0 codebase. The cache continues to evolve, but the core architectural principles remain consistent across versions.