Kubernetes Scheduler Cycles and API Integration
The Complete Execution Model

This is part of a series of blog posts exploring the Kubernetes kube-scheduler from the perspective of someone who has dug deep into the codebase.
Introduction
Today, we’re going to dive deep into the complete execution model of Kubernetes scheduling, examining the scheduling cycles, the API Dispatcher that handles binding operations, and the event-handling system that keeps everything synchronized.
Part 1: The Synchronous Scheduling Cycle
To better understand the synchronous scheduling cycle, let’s walk you through a detailed flowchart that shows the decision points, plugin execution, and error handling:
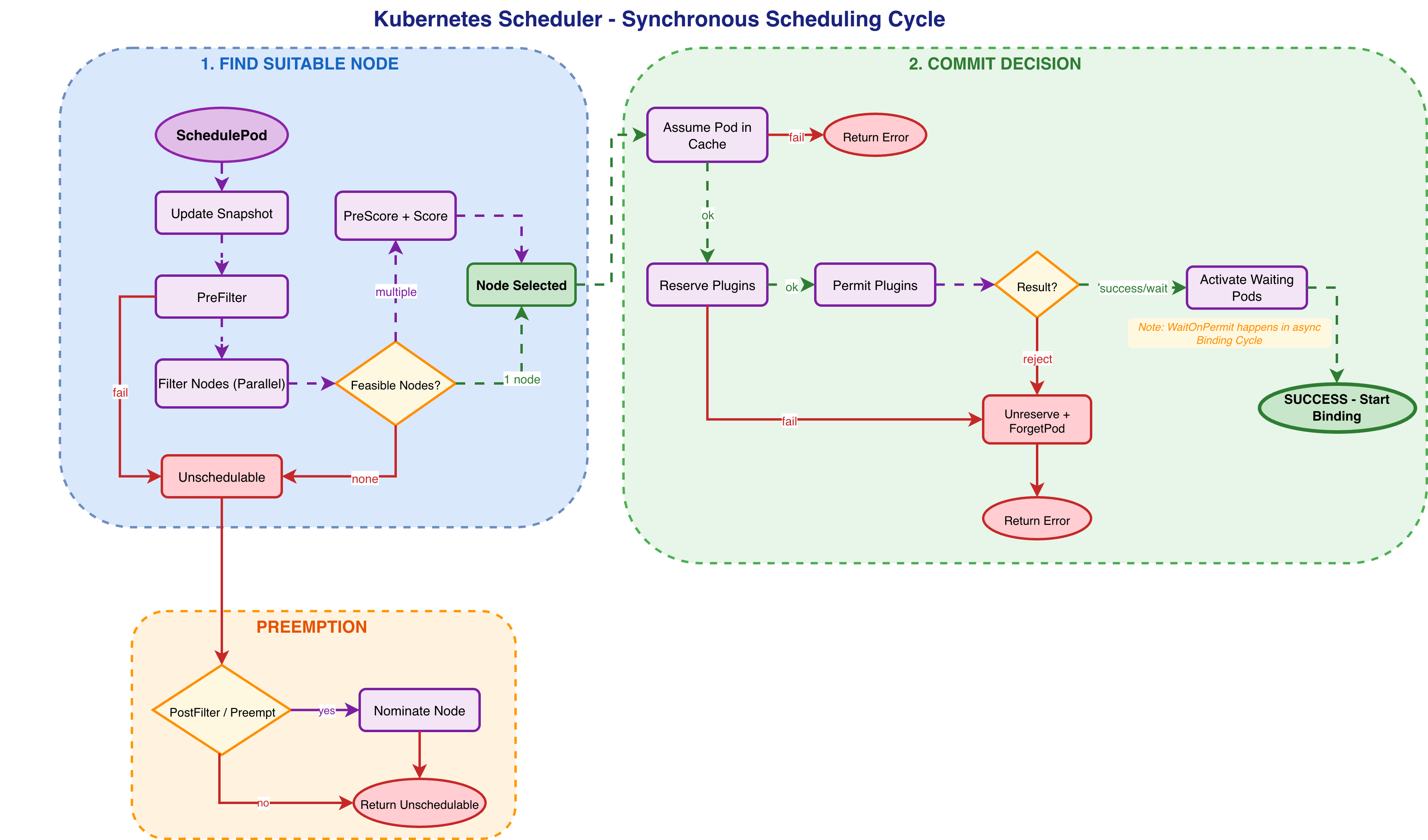
The ScheduleOne Function: The Entry Point
When you dig into the codebase, you will find that the`ScheduleOne` function is the heart of the scheduler. It orchestrates the entire scheduling workflow: retrieves a pod from the queue, runs the synchronous scheduling cycle to select a node, and then launches an asynchronous goroutine to handle the binding cycle.
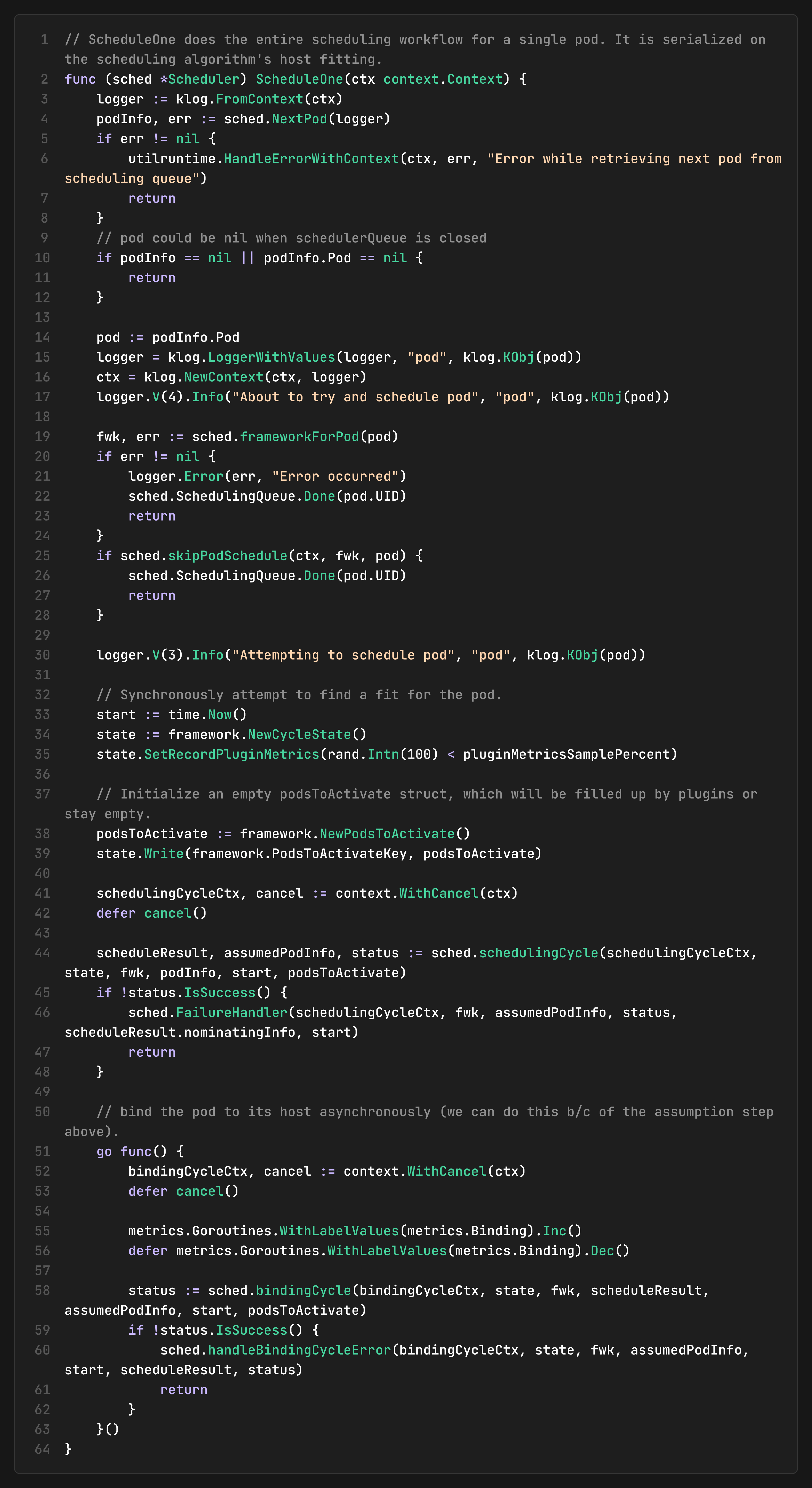
The `ScheduleOne` function orchestrates both cycles:
Synchronous Scheduling Cycle: Runs immediately and determines where to place the pod
Asynchronous Binding Cycle: Runs in a separate goroutine and handles the actual binding
This separation is essential to the scheduling workflow, since the scheduling cycle must be fast and deterministic, whereas the binding cycle can take time. It may fail, even though the pod is “assumed” to be scheduled after the scheduling cycle completes.
Evolving to Opportunistic Batching
The name `ScheduleOne` reflects its design: process one pod at a time. While this ensures simplicity and determinism, it limits throughput in large clusters. KEP-5598: Opportunistic Batching (`OpportunisticBatching`, beta in v1.35) evolves this model by reusing filter/score results.
Scheduling remains sequential, which means the optimization is result caching, not parallel execution.
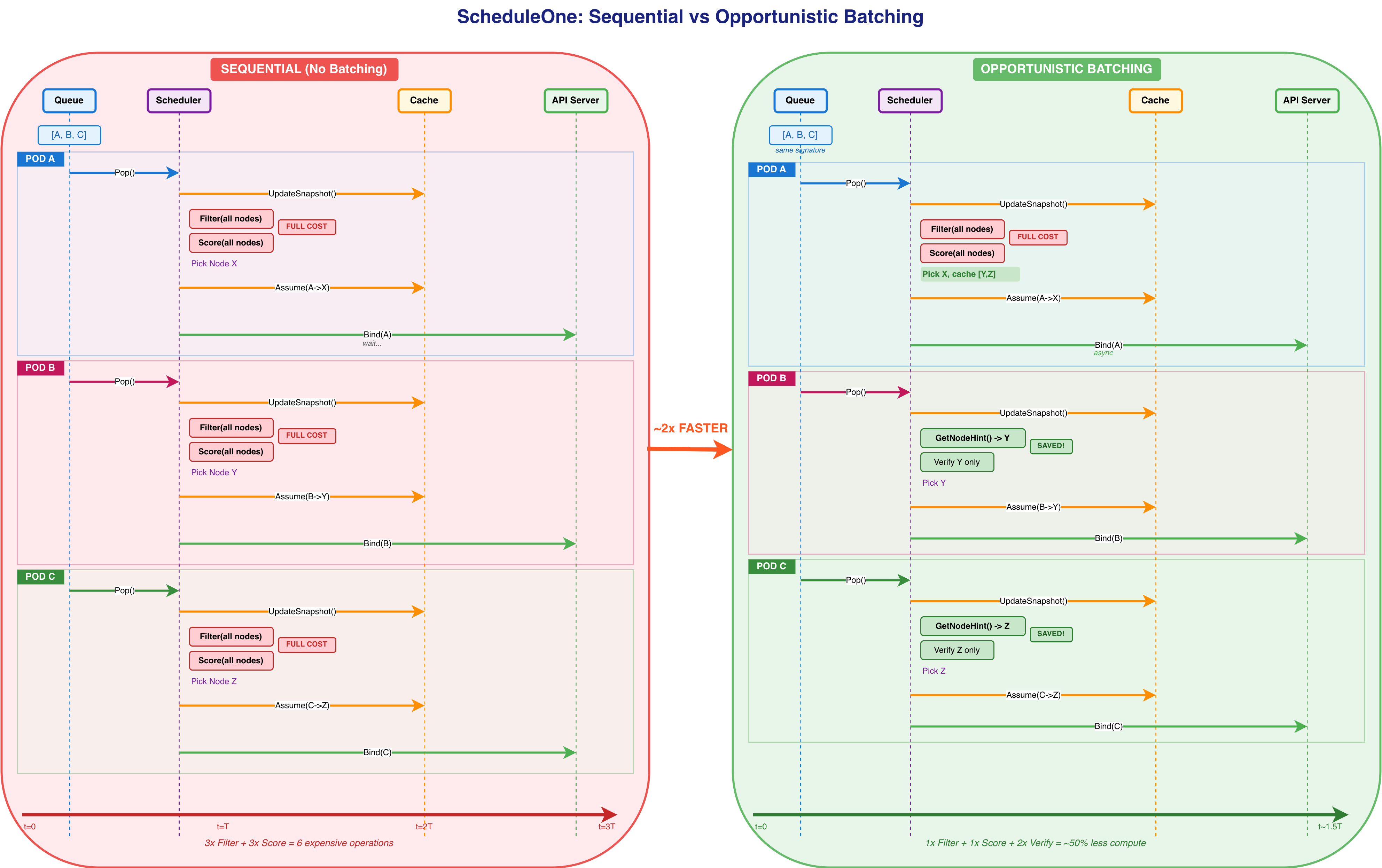
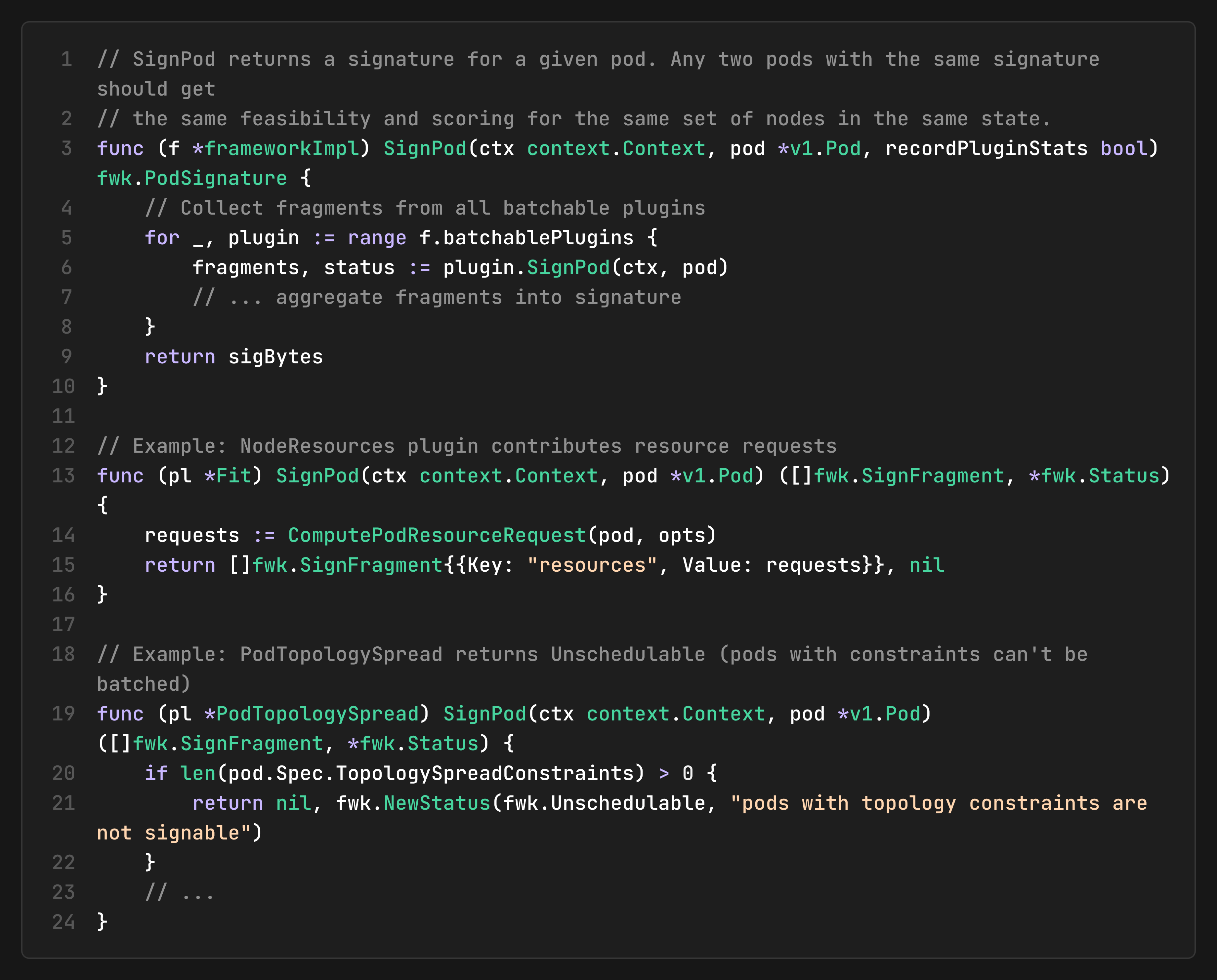
How it works
SignPod: Each pod gets a “signature” computed from plugin-specific traits. Plugins implement `SignPod` to contribute signature fragments:
Result Caching: After scheduling Pod A, the scheduler caches the sorted list of feasible nodes (excluding the chosen node).
GetNodeHint: For subsequent pods with matching signatures, the scheduler retrieves the next-best node from the cache rather than rerunning all filter/score plugins.
Verification: The hinted node is verified using a single-node filter check to confirm it remains feasible.
Conditions for batching to work
Consecutive pods must have the same signature
The previous scheduling cycle must have succeeded
Cached results must not be older than 500ms (`maxBatchAge`)
The previously chosen node must now reject the new pod (one-pod-per-node constraint)
This enables faster scheduling for batch workloads with identical pods, reducing compute by ~50% for compatible pods while maintaining correctness through verification.
The Scheduling Cycle Implementation
The `schedulingCycle` function is where the actual node selection happens. It runs synchronously and must complete before the scheduler can process the next pod. The function calls `SchedulePod` to find a suitable node, handles failures by triggering preemption via PostFilter plugins, and if successful, assumes the pod in the cache and runs Reserve/Permit plugins to commit the decision.
Key Characteristics of the Synchronous Cycle
Speed: The synchronous cycle must be fast because it blocks the scheduler from processing other pods.
Determinism: The cycle must be deterministic and provide consistent results. All plugins see the same cluster state through the snapshot mechanism.
Atomicity: The cycle either succeeds completely or fails completely. If any step fails, all previous steps are rolled back.
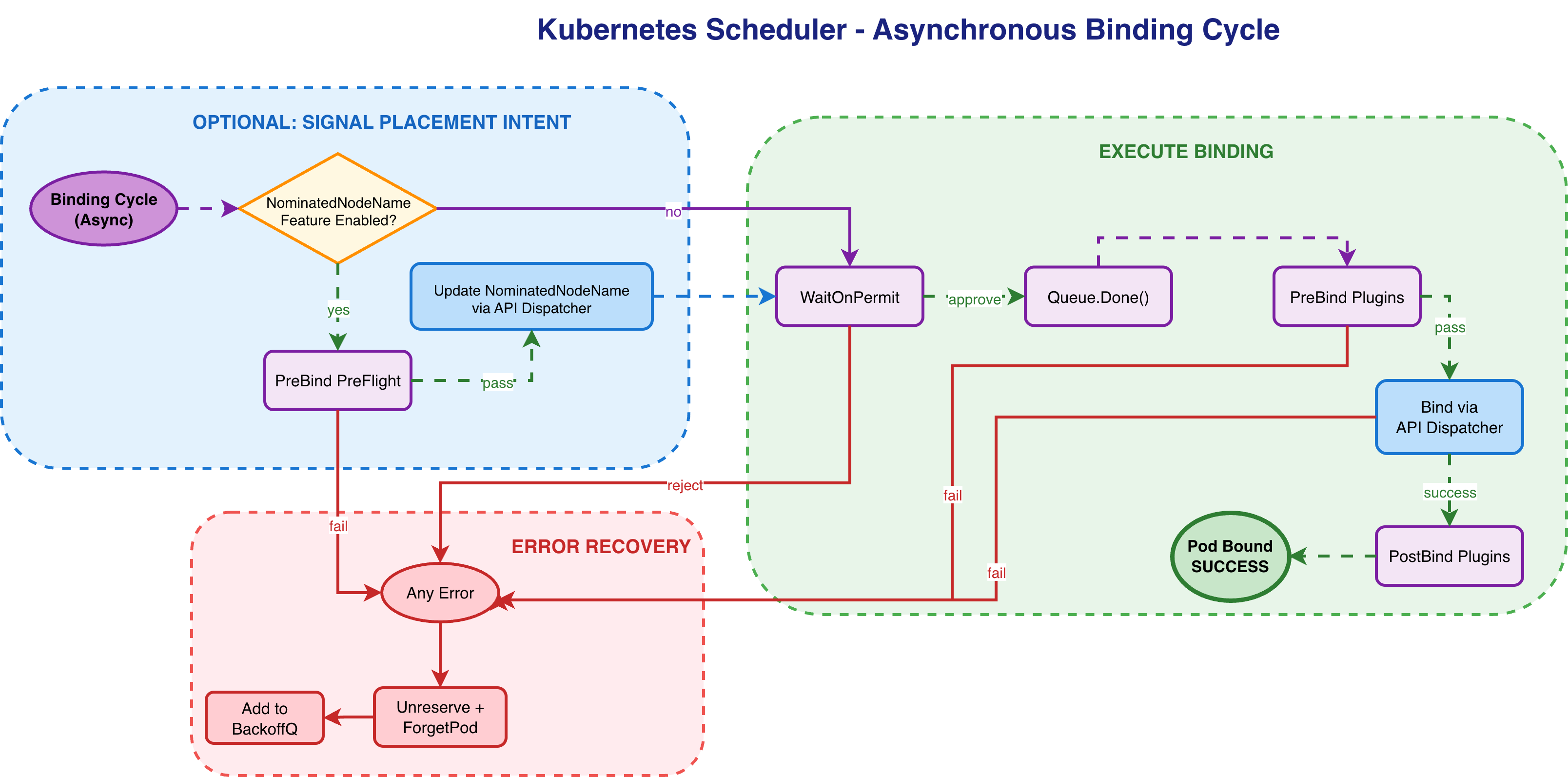
Part 2: The Asynchronous Binding Cycle and API Dispatcher
The binding cycle handles the pod’s actual binding to the node. It runs in a separate goroutine and integrates with the API Dispatcher, which manages asynchronous API operations.
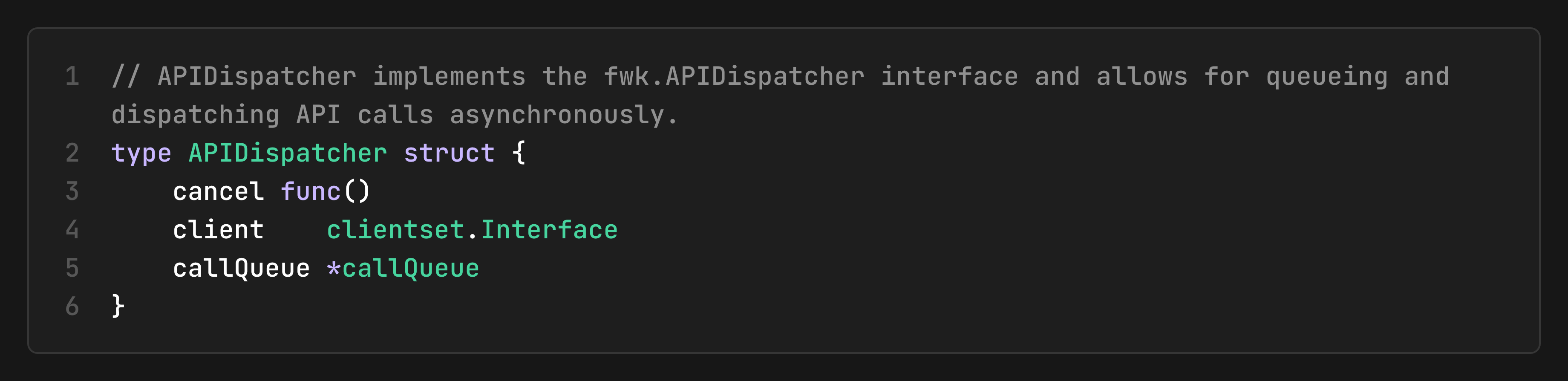
The API Dispatcher: Managing Asynchronous API Calls
The APIDispatcher is the scheduler’s interface to the external world, handling all interactions with the Kubernetes API Server asynchronously. It can be enabled via the 'SchedulerAsyncAPICalls` feature gate (beta since v1.34).
When enabled, this feature routes all scheduler API calls (binding, status updates, preemption) through the API Dispatcher rather than making synchronous API calls. This provides:
Non-blocking operations: The scheduler doesn’t wait for API responses
Call deduplication: Redundant calls for the same object are merged
Better metrics: Centralized tracking of all API interactions
Graceful handling: Failed calls don’t block the scheduling loop
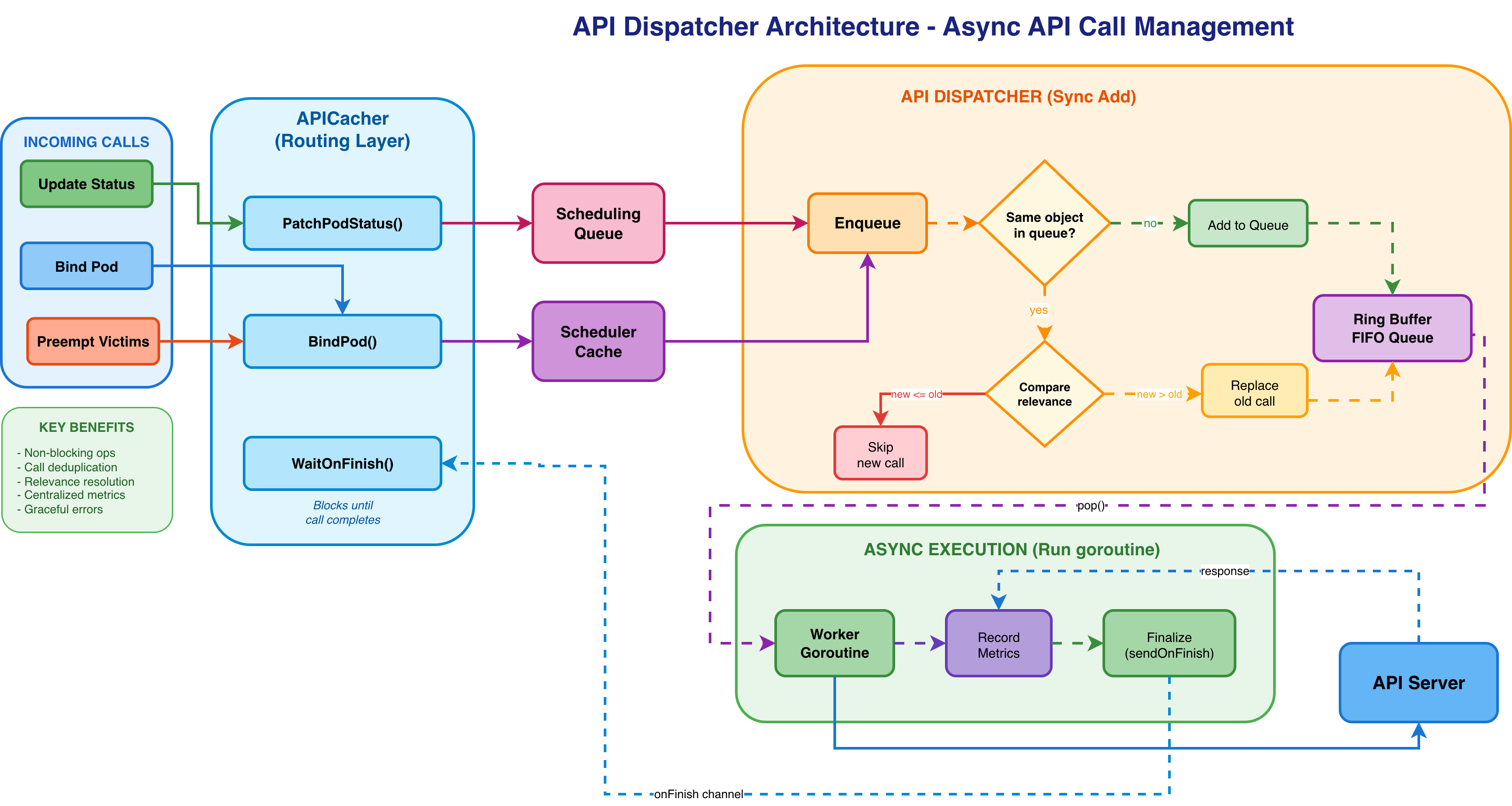
The APICacher as a Routing Layer for Async Operations
The `APICacher` sits between the scheduler and the API Dispatcher, routing different types of API calls through appropriate paths:
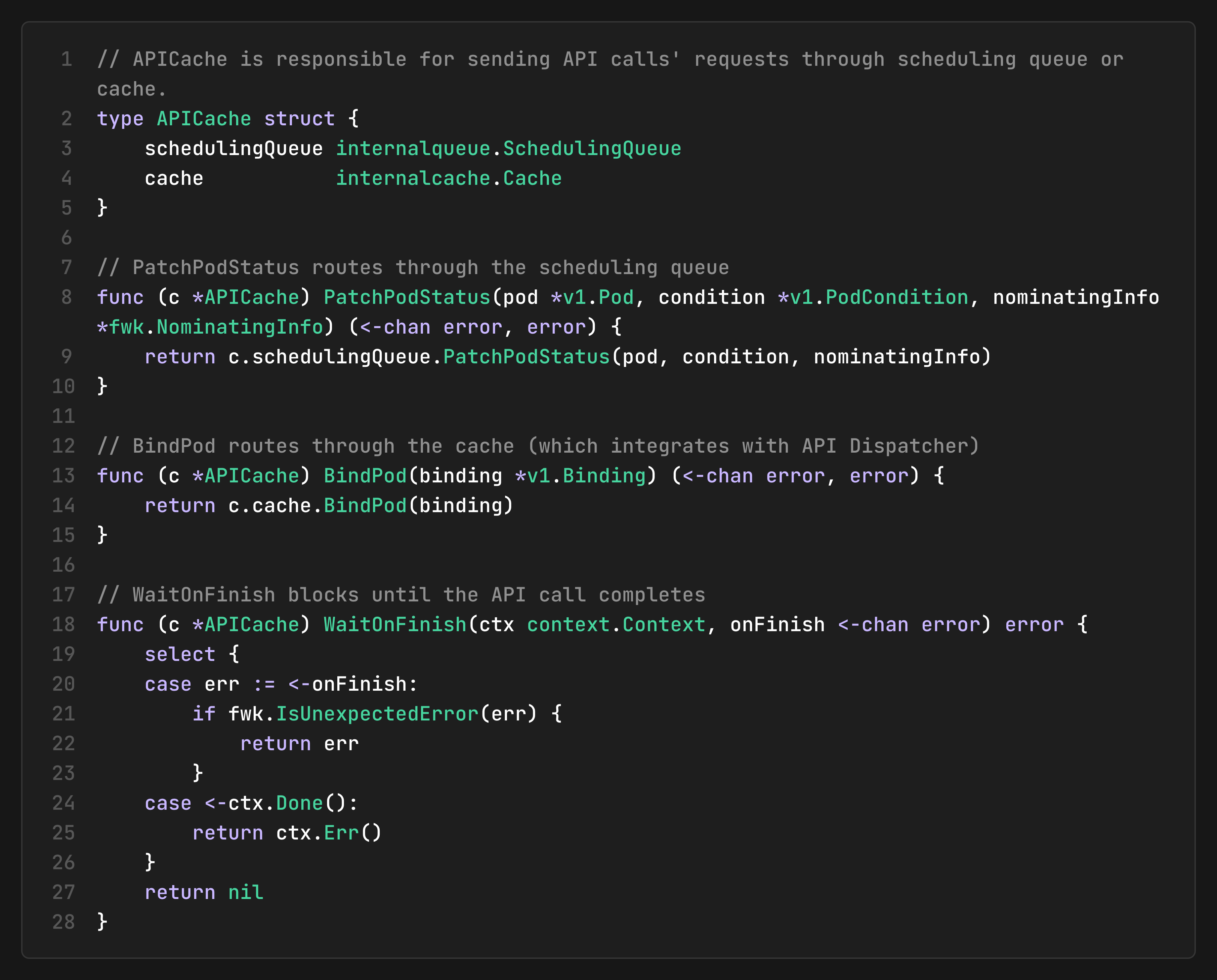
This separation allows:
Status updates to be coordinated with the scheduling queue (for proper event ordering)
Bind operations to be coordinated with the cache (for assumption management)
Async result waiting through the `WaitOnFinish` helper
API Dispatcher Architecture
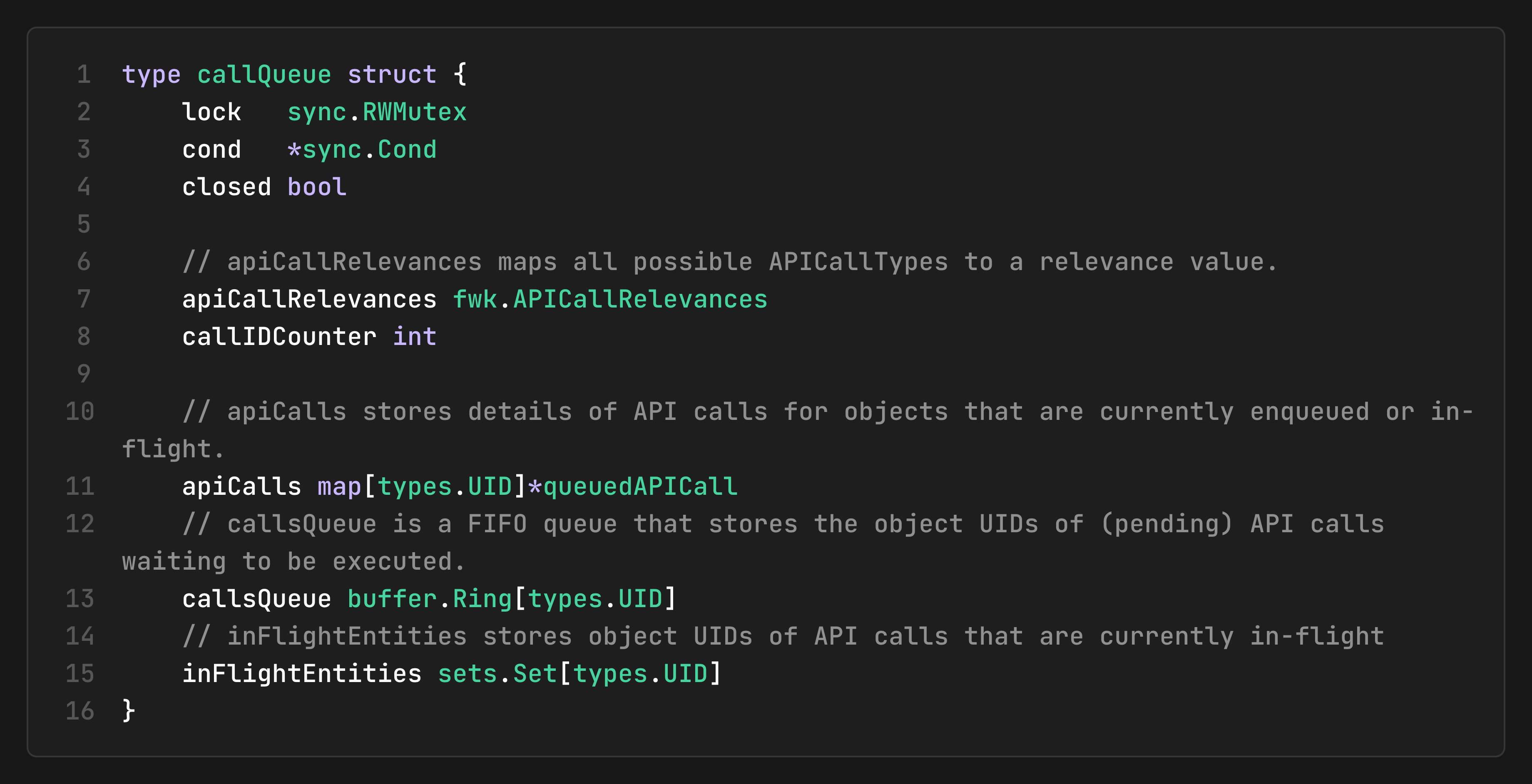
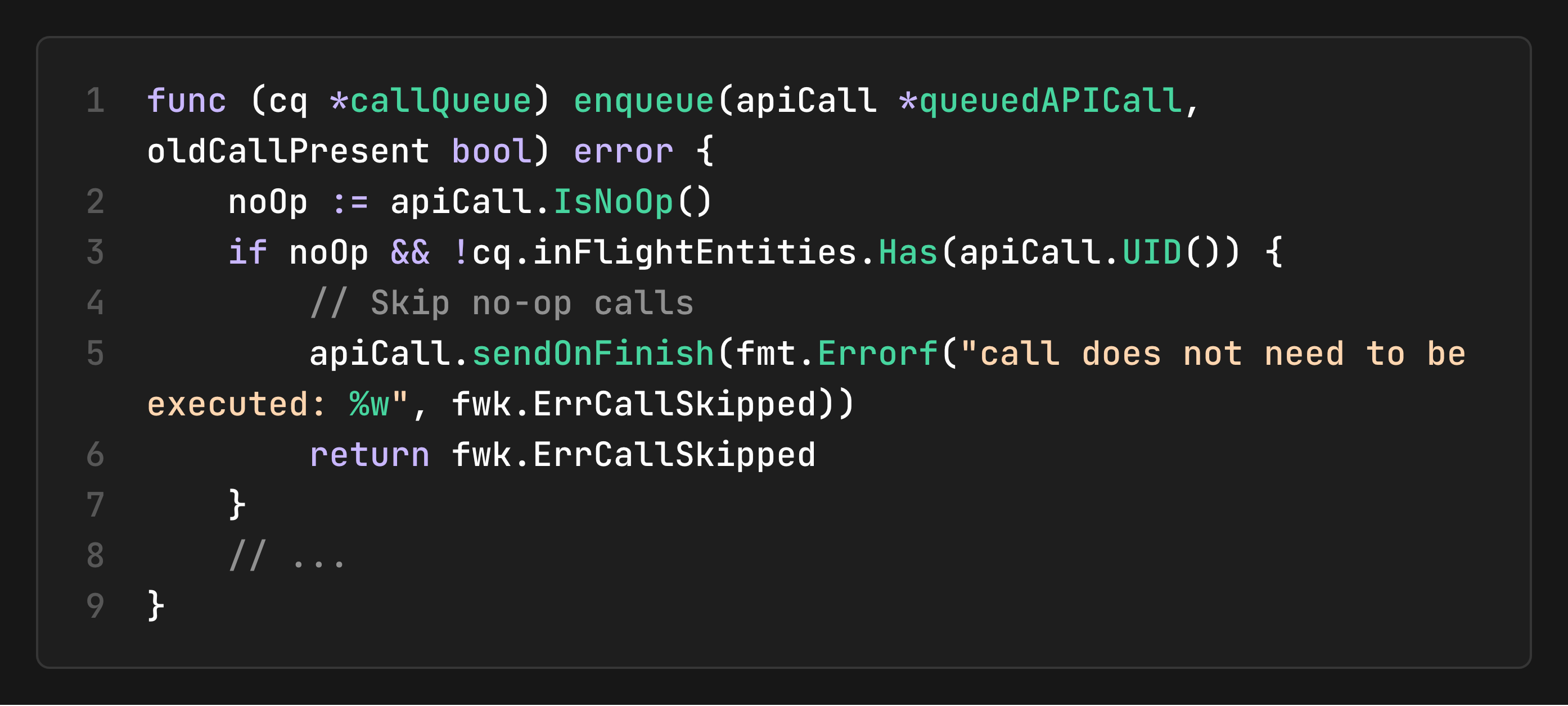
The Call Queue for API Call Management
The callQueue manages API calls for handling concurrent operations:
Key mechanisms
Object-Level Serialization: For any given object (identified by its UID), at most one API call is queued at any time, preventing race conditions.
Call Merging and Overwriting: When a new call is added for an object that is already being tracked, the controller reconciles them by merging, overwriting, or skipping based on relevance.
In-Flight Tracking: The controller tracks all call states (pending, in-flight) to coordinate asynchronous execution.
Relevance-Based Call Resolution
When multiple API calls target the same object, the dispatcher uses a relevance system to decide which call wins:

The resolution logic:
New call more relevant: Replace the old call, notify the old caller with `ErrCallOverwritten`
New call less relevant: Skip the new call and notify the new caller with `ErrCallSkipped`
Same type: Merge the calls if possible (i.e., combining status updates)
In-flight call exists: Queue the new call to run after the current one completes
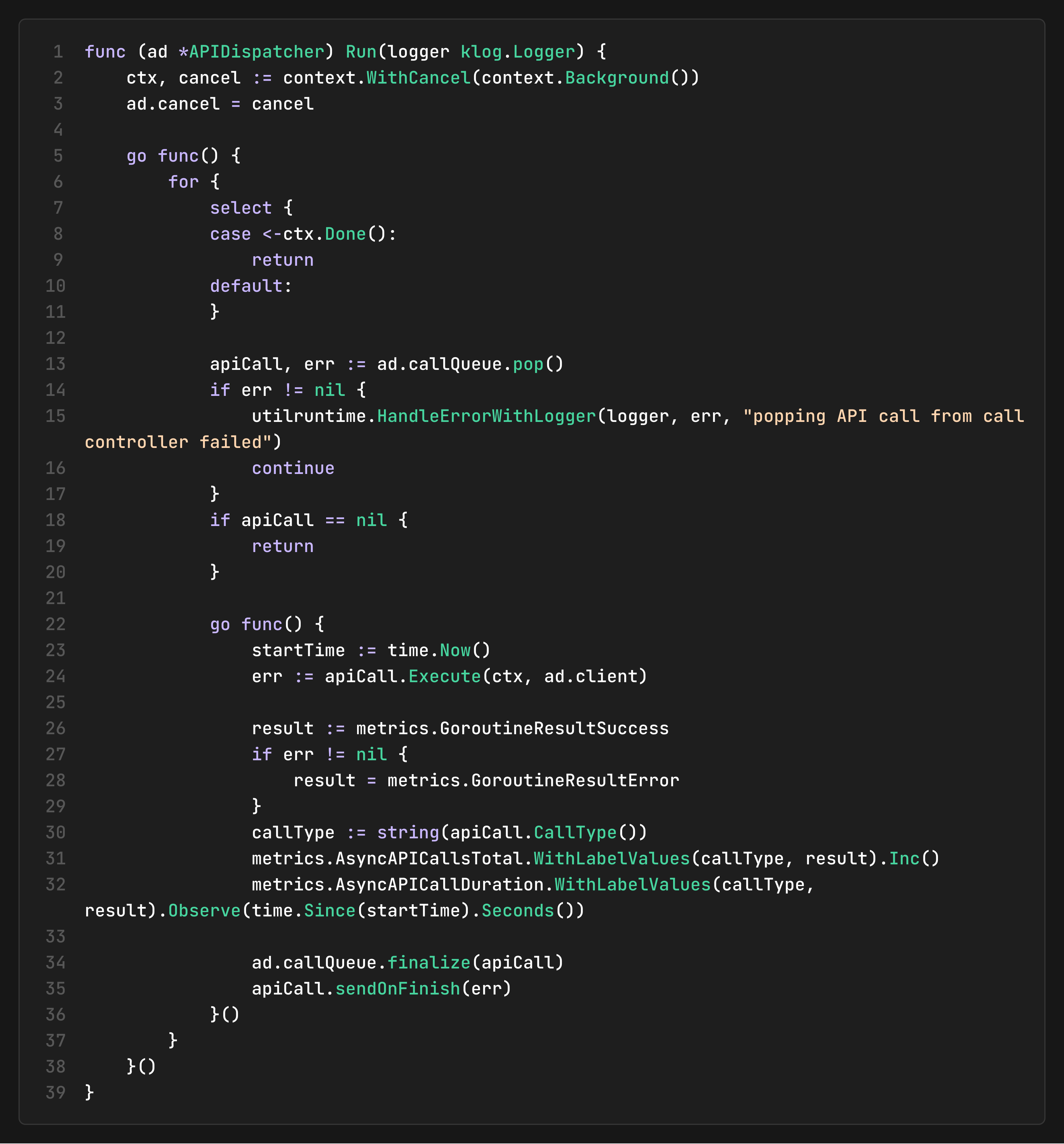
The Execution Loop
The `Run` method starts a background goroutine that continuously pops calls from the queue and executes them against the API server. Each call runs in its own goroutine, enabling concurrent API operations while the loop proceeds to the next call. After execution, it records latency metrics and finalizes the call to unblock any waiters.
The Binding Cycle Implementation
The `bindingCycle` runs asynchronously after the scheduling cycle completes, allowing the scheduler to process the next pod immediately. It waits for any Permit plugin approvals, executes PreBind/Bind/PostBind plugins in sequence, and commits the pod-to-node assignment to the API server. If any step fails, the assumed pod is removed from the cache and returned to the queue.
Part 3: The Scheduler’s Event Handling
The event handling system makes the scheduler reactive to cluster changes. It processes events from informers and triggers appropriate actions in the cache and queue.
Event Handler Registration
The scheduler registers event handlers for multiple Kubernetes resources:
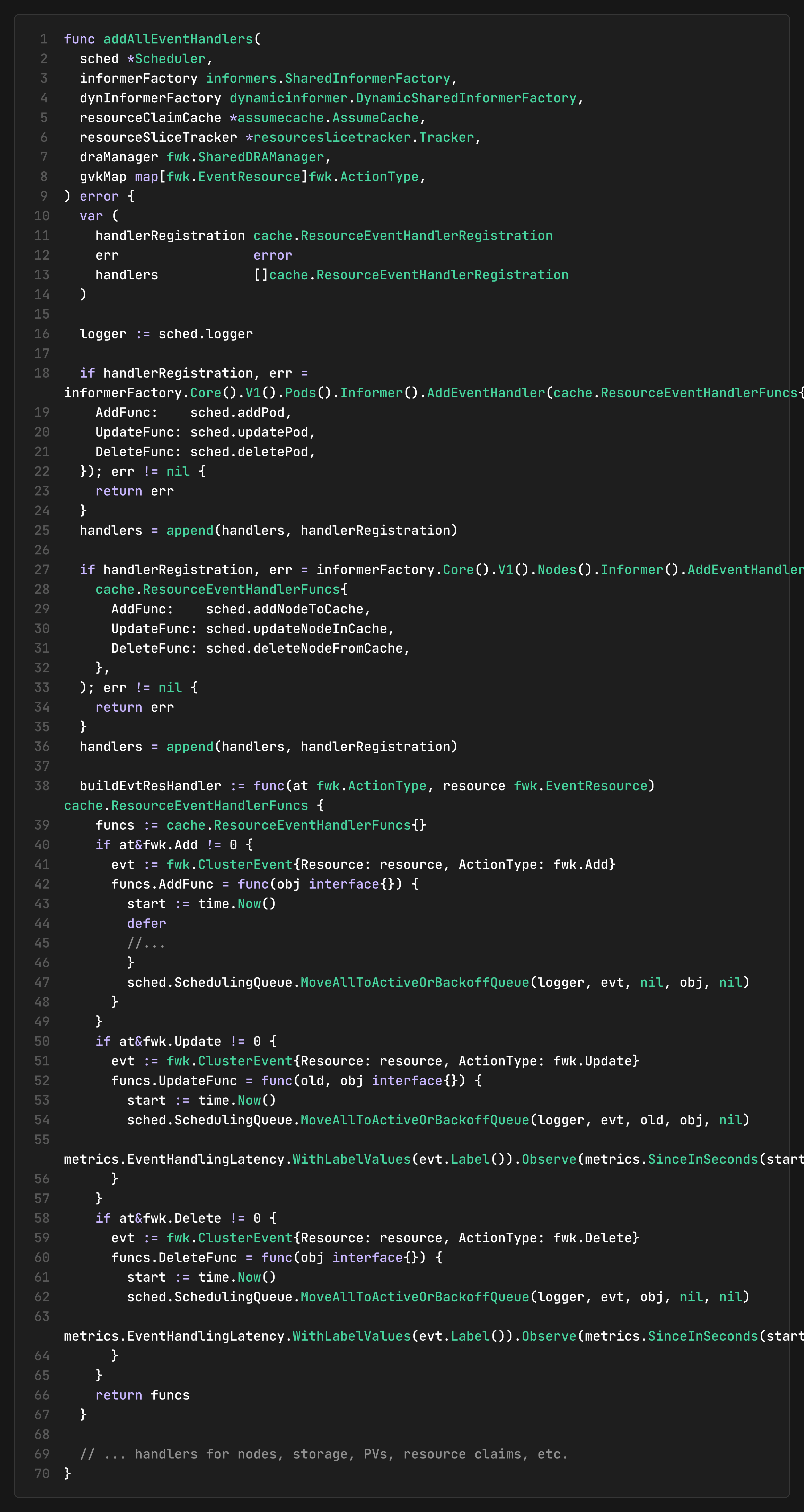
Event Processing Flow
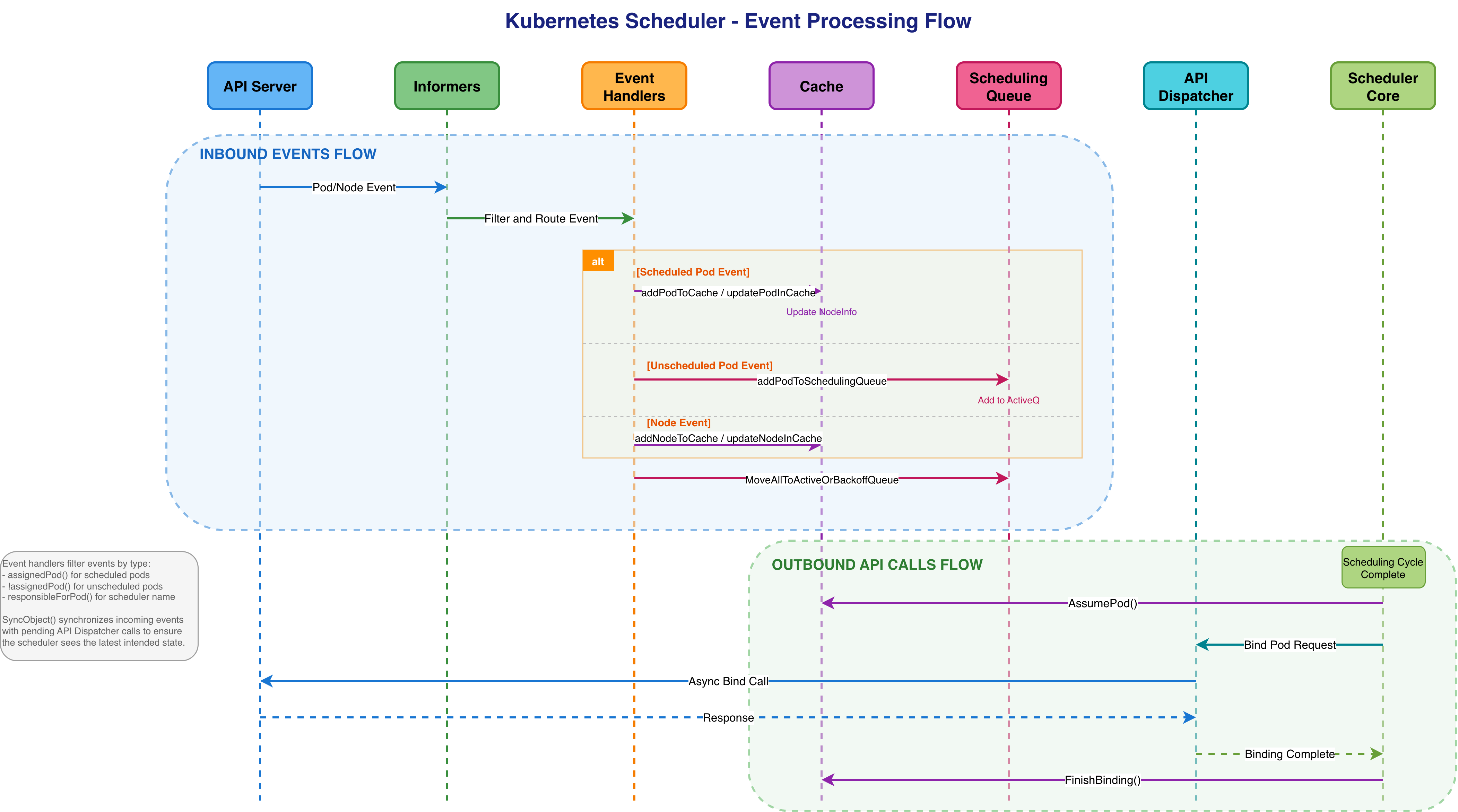
The diagram above illustrates two parallel flows in the scheduler:
Inbound Events Flow: Events from the API Server are received via Informers and processed by Event Handlers. The handlers filter events by type using helper functions such as `assignedPod()`, `!assignedPod()`, and `responsibleForPod()` to verify scheduler ownership. Based on event type:
Scheduled Pod Events: Route to Cache via `addPodToCache`/`updatePodInCache`, updating NodeInfo
Unscheduled Pod Events: Route to Scheduling Queue via `addPodToSchedulingQueue`, adding to ActiveQ
Node Events: Update Cache and trigger `MoveAllToActiveOrBackoffQueue` to re-evaluate waiting pods
Outbound API Calls Flow: After the scheduling cycle completes, the Scheduler Core calls `AssumePod()` to optimistically update the cache, then initiates a Bind Pod Request through the API Dispatcher. The dispatcher sends an async bind call to the API Server. Upon response, it signals Binding Complete and calls `FinishBinding()` to finalize the cache state.
Event Synchronization with API Dispatcher
When the scheduler receives events from informers, it must account for pending API calls that haven’t yet been reflected in the API server. The `SyncObject` method synchronizes incoming events with pending dispatcher calls:
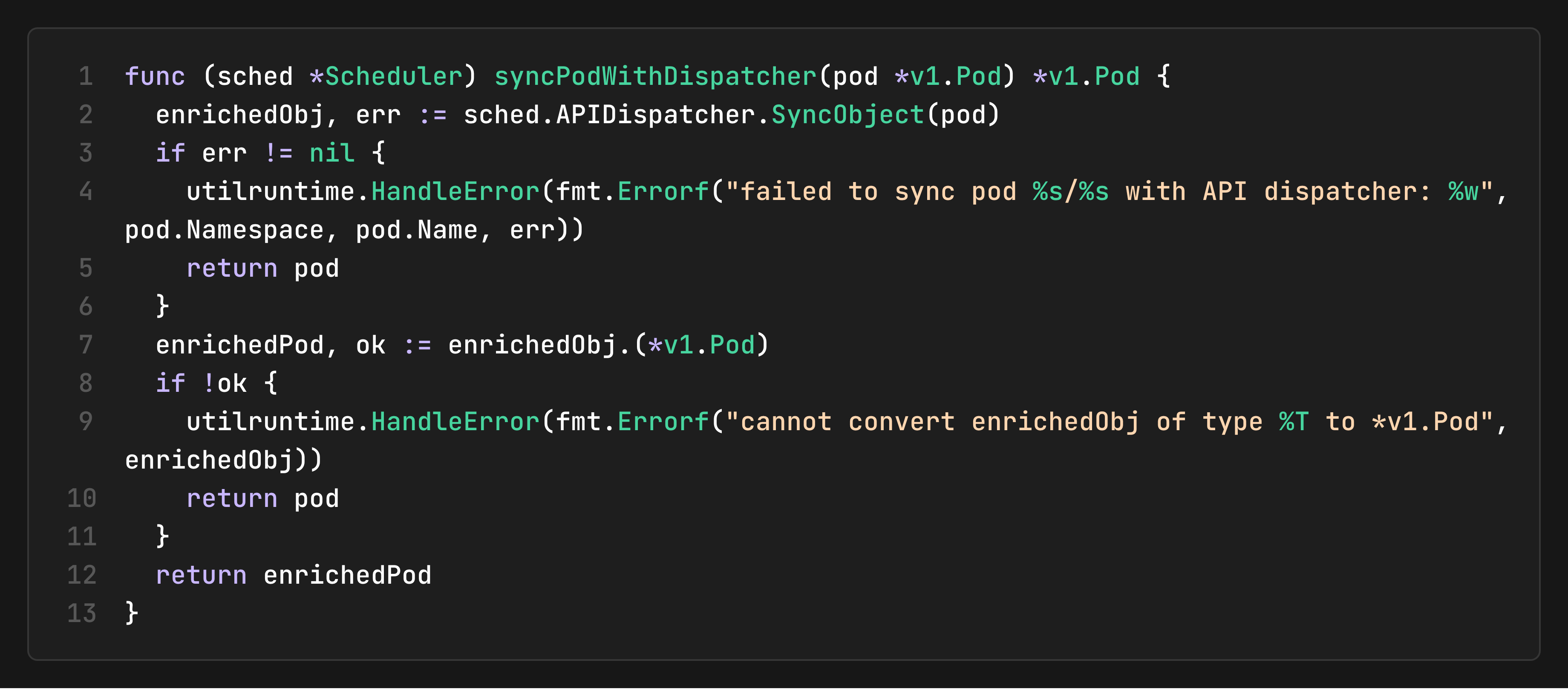
This ensures the scheduler sees the latest intended state (including pending updates) rather than potentially stale data from the informer cache.
Handling Assumed Pod Deletion
A critical edge case occurs when an assumed pod is deleted during its binding cycle:
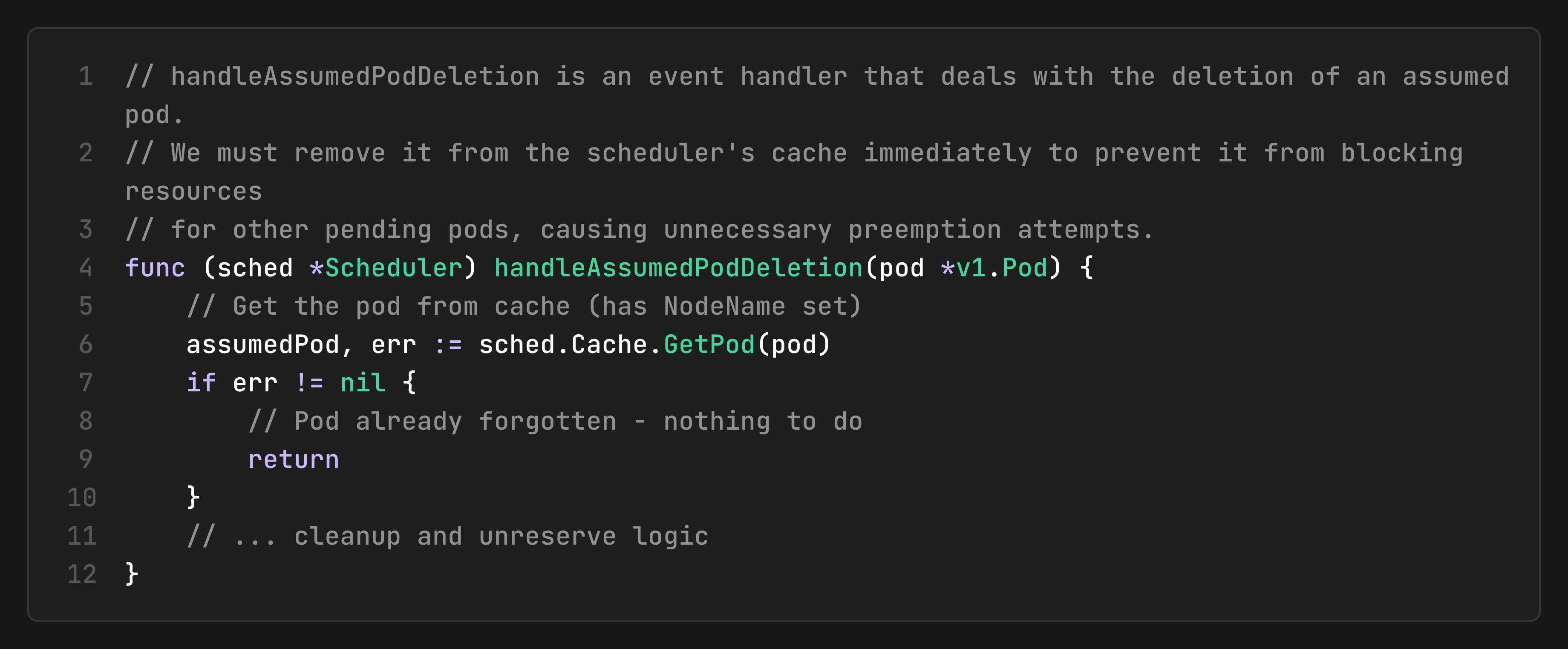
This prevents resource leaks when pods are deleted mid-flight.
Event-Driven Queue Movements
When cluster events occur, they can trigger pod movements between queues:
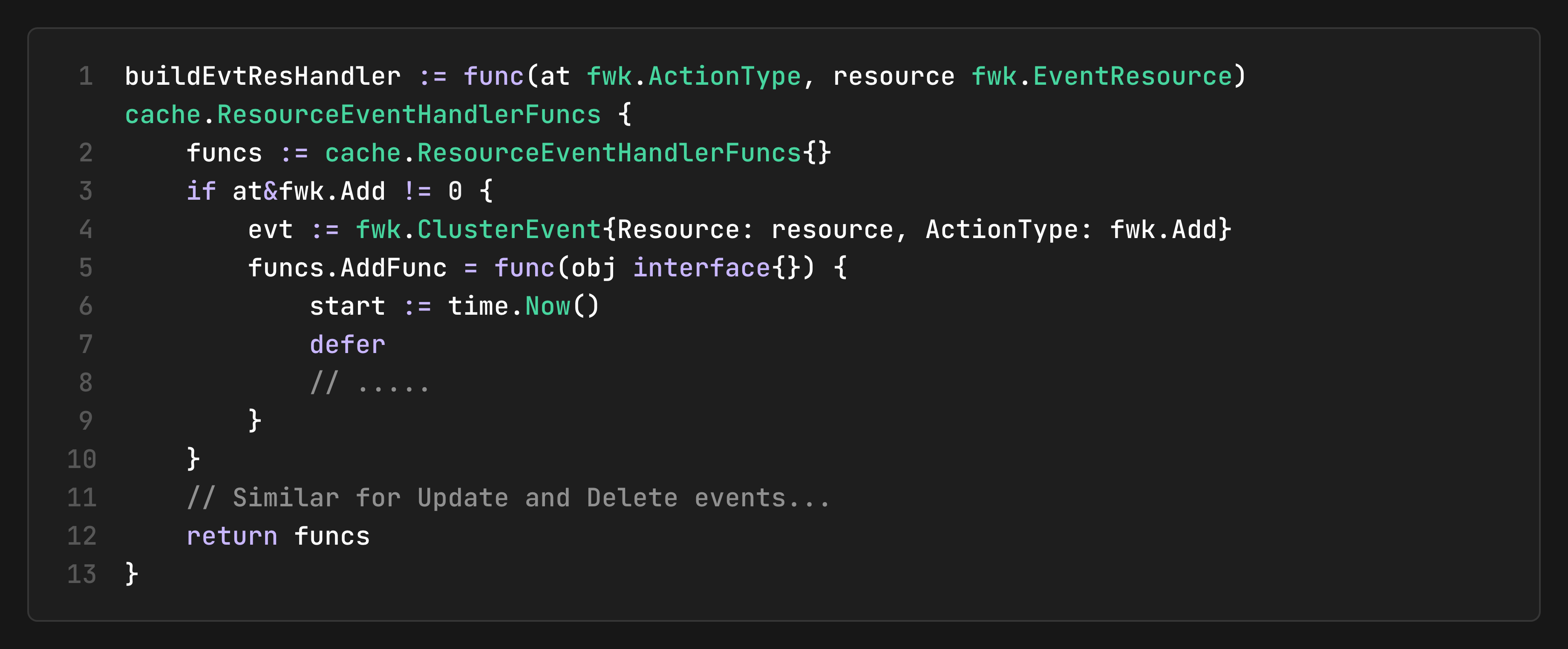
This integrates with the queueing hints system covered in Event-Driven Pod Movements: The Queue’s Intelligence to intelligently move only affected pods.
Part 4: Coordinating Everything
The Assumption Mechanism - Bridging the Cycles
The assumption mechanism enables the separation between the synchronous scheduling cycle and the asynchronous binding cycle. I covered the cache’s pod state machine in detail in Kubernetes Scheduler Cache-> Assumed Pods(Optimistic Scheduling). Here’s how it bridges the cycles:
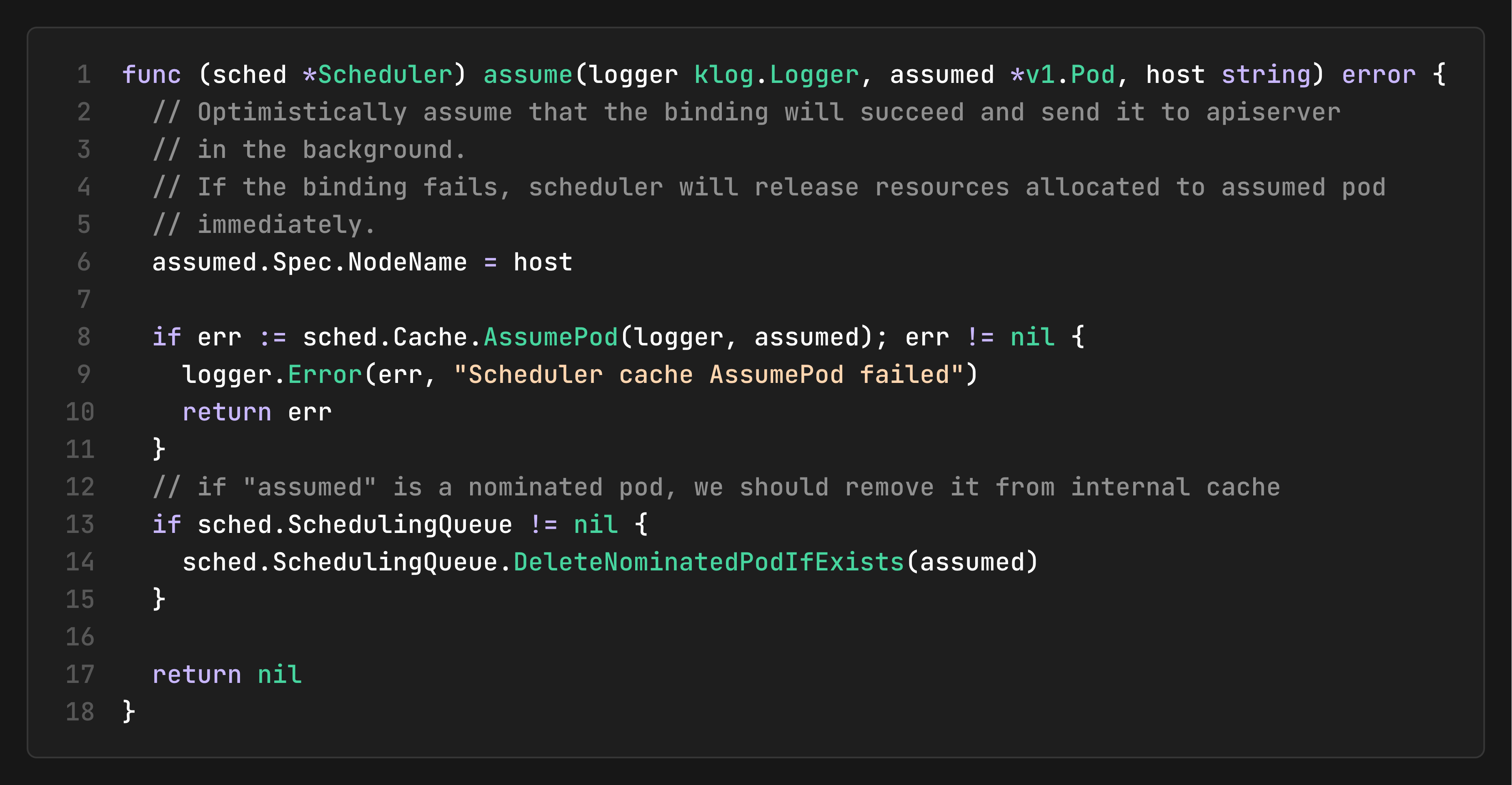
At this moment:
The scheduling cycle has completed (found a suitable node)
The cache now reflects this pod’s resource usage
The binding cycle can proceed asynchronously via the API Dispatcher
Without the assumption, the scheduler would have to wait for the API server’s confirmation before processing the next pod. The assumption mechanism creates a pipeline:
Pod A: Scheduling complete, binding in progress via API Dispatcher
Pod B: Scheduling in progress (sees Pod A’s resources as consumed)
Pod C: Waiting in the queue
The Run Loop: Orchestrating everything
The `Run` method bootstraps all components and starts the scheduling loop. It initializes the Scheduling Queue, starts the API Dispatcher for async operations, and launches `ScheduleOne` in a continuous loop. On shutdown, it gracefully closes all components in reverse order.
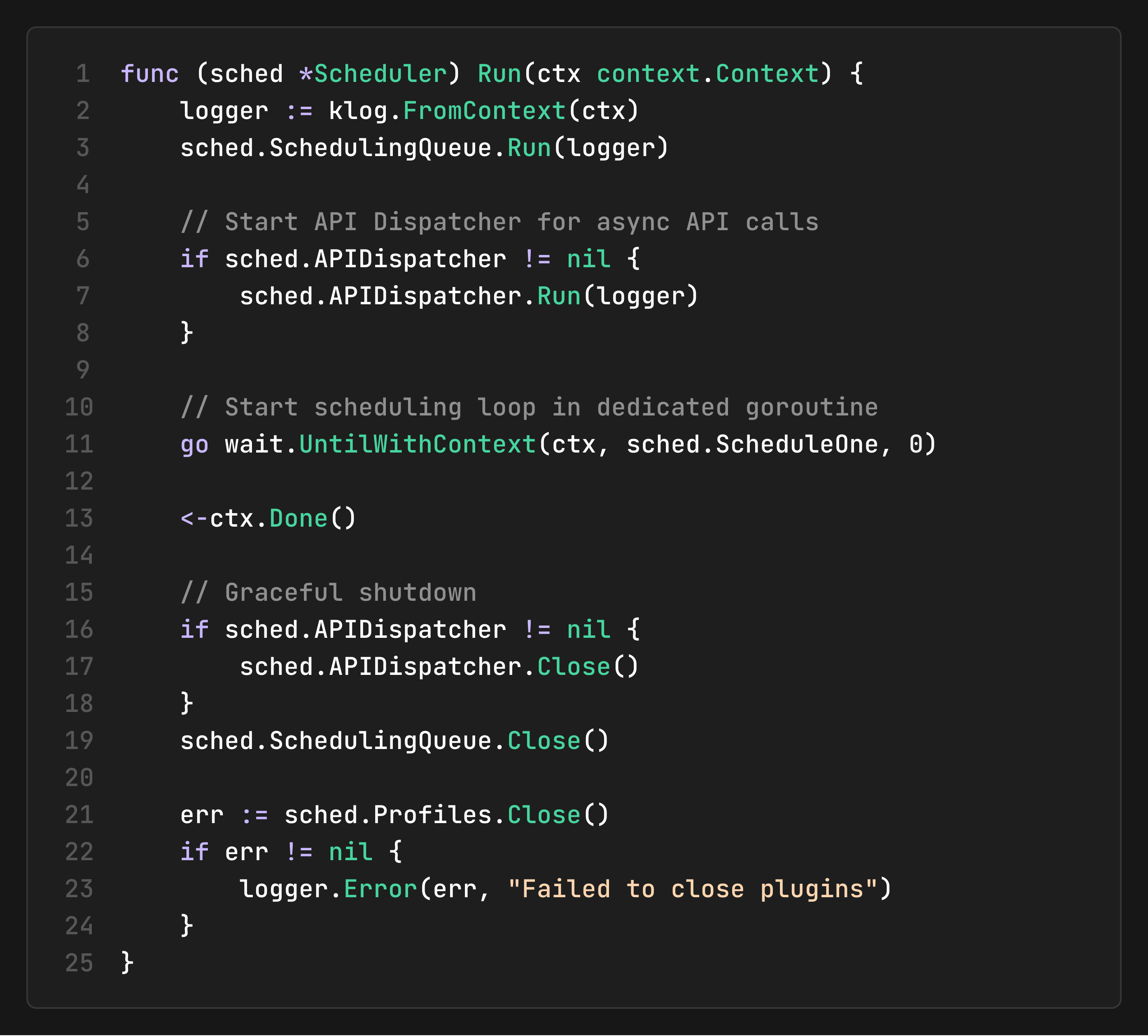
Error Handling Across Cycles
Scheduling Cycle Errors
Rollback: Reserve plugins call Unreserve
Queue Routing: Pod moves to appropriate queue (see The Three-Queue Architecture)
Cache: Remains unaffected (no assumption made yet)
Binding Cycle Errors
Assumption Cleanup: `ForgetPod` removes the assumed pod (see Pod State Machine)
Resource Release: Unreserve plugins are called to release any resources claimed during Reserve (i.e., PVC bindings, port allocations)
Retry: Pod moves to backoff queue
Performance Optimizations
The scheduler implements several optimizations to handle high pod throughput while minimizing latency and resource consumption.
Metrics Sampling
To reduce overhead, plugin-level metrics are recorded only for a percentage of scheduling cycles rather than every cycle. This provides statistical visibility without impacting performance.

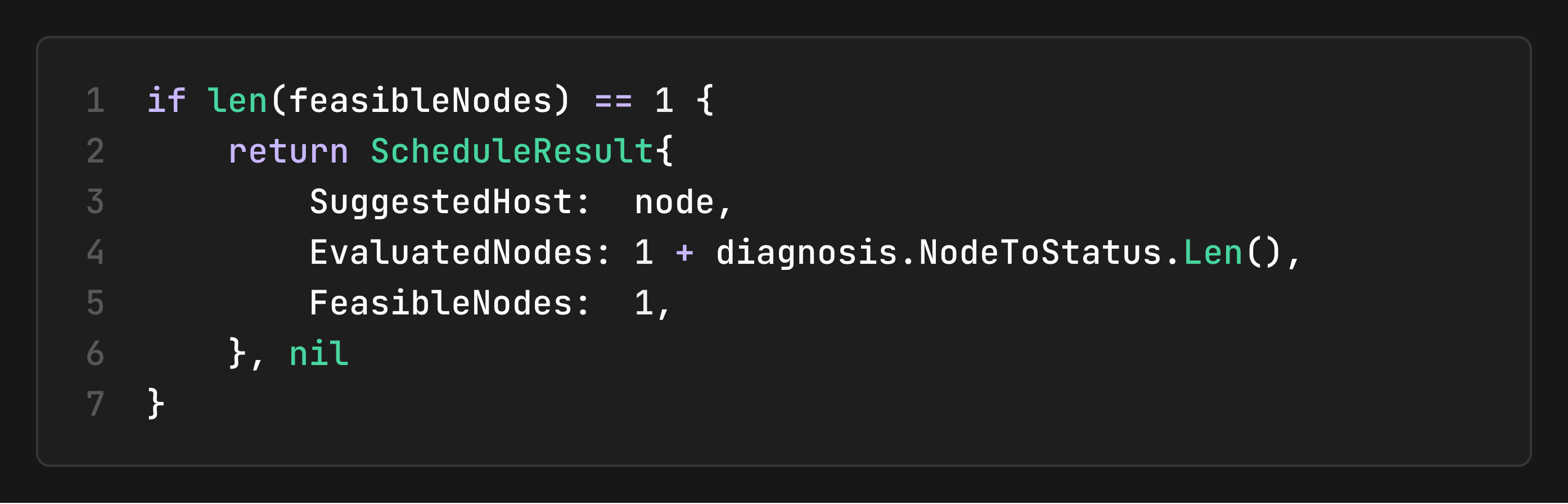
Single Node Fast Path
When only one node passes the filtering phase, the scheduler skips scoring entirely since there’s no decision to make. This avoids unnecessary computation and returns the result immediately.
API Dispatcher Call Merging
The API Dispatcher prevents unnecessary API calls by merging compatible operations and skipping no-ops:
This analysis is based on Kubernetes v1.35 codebase. The scheduler continues to evolve, but the core architectural principles remain consistent across versions.